Shin x blog
Laravel 4 データベースを使ったテストで Migration と Seeder を使う
Laravel 4 でデータベースを使ったテストを書く際の Tips です。

自動テストでデータベースにアクセステストを書く際に大切なのが、データベーステーブルのデータをテストで想定された状態にしておくということです。テーブルの内容がテストを実行される度に異なると、ある時はテストが通って、ある時は通らないという状態になります。
この「想定された状態」をセットアップするために、フレームワークで用意されている Migration と Seeder を利用しています。
テストケースでマイグレーション実行
開発を進めていると、データベーススキーマを変更する場合があります。マイグレーションファイルを作成して、php artisan migrate コマンドで適用するのことになります。テスト用データベースについても適用する必要がありますが、php artisan migrate --env=testing を実行するのは、少し手間なので、テストケースで実行するようにしています。
artisan コマンドは、PHP コードでは、Artisan::call() で実行できるので、下記のようにすると、テストクラスでマイグレーションを実行することができます。
<?php
public function setUp()
{
parent::setUp();
Artisan::call('migrate');
}
ただ、マイグレーションは、全てのテストケースで毎回実行する必要が無いので、基底クラスである TestCase に下記のように実装して、初回のみ実行するようにしています。
<?php
class TestCase extends IlluminateFoundationTestingTestCase
{
protected static $databaseSetup = false;
/**
*
*/
protected function setUpDatabase()
{
if (static::$databaseSetup) {
return;
}
Artisan::call('migrate');
static::$databaseSetup = true;
}
/**
* Creates the application.
*
* @return SymfonyComponentHttpKernelHttpKernelInterface
*/
public function createApplication()
{
$unitTesting = true;
$testEnvironment = 'testing';
return require __DIR__ . '/../../bootstrap/start.php';
}
}
データベースを使うテストクラスでは、下記のように setupDatabase メソッドを実行して、マイグレーションを実行します。(実際にマイグレーションが実行されるのは初回のみ)
<?php
class FooTest extends TestCase
{
public function setUp()
{
parent::setUp();
$this->setUpDatabase();
}
}
フィクスチャとして Seeder を使う
Laravel には、テーブルのデータを一括登録する仕組みとして Seeder があります。テーブルへの登録処理を書いておくと、php artisan db:seed コマンドでデータを登録することができます。主にアプリケーションで必要なマスタデータや初期データを投入するのに使われますが、これをテスト時のフィクスチャとして利用します。
Seeder クラスは、app/database/seeder 以下に配置するのが通常なのですが、フレームワークとしては、オートローダーで読み込むことができれば、どこに配置しても構いません。
テスト用の Seeder クラスは、テストケースと密接な関係にあり、テストに応じたレコードを用意する必要があるので、同じ PHP ファイルに定義しています。クラス名は、テストケースクラス名の後ろに Seeder を付けています。こうすれば、どのテストケースでも、同じファイルにある Seeder クラスを __CLASS__ . 'Seeder'で参照できます。
<?php
class FooTest extends TestCase
{
public function setUp()
{
parent::setUp();
$this->setUpDatabase();
$this->seed(__CLASS__ . 'Seeder');
}
}
class FooTestSeeder extends Seeder
{
public function run()
{
Eloquent::unguard();
Item::truncateAll();
Item::create(
[
'id' => 1,
'name' => '商品1',
'price' => 100,
]
);
}
}
Item::truncateAll() は、PostgreSQL 環境で、truncate を実行するために独自に実装したメソッドで、下記のような実装になっています。TRUNCATE 文に RESTART IDENTITY CASCADE を付けることで、テーブルのシーケンス値のリセットと、このテーブルを外部参照しているテーブルを同時に削除することができます。
<?php
class AppModel extends Eloquent
{
/**
* for test
*/
public static function truncateAll()
{
$table = (new static)->getTable();
$sql = 'TRUNCATE ' . $table . ' RESTART IDENTITY CASCADE';
DB::table($table)->getConnection()->statement($sql);
}
}
複数のテストケースで共有する場合は、app/database/seeder に配置して、$this->seeder('TestCommonSeeder') などで実行します。
さいごに
冒頭に書きましたが、データベースを利用したテストでは、事前に想定した環境を作っておくことが肝になります。
Seeder をフィクスチャとして使うことで、アプリケーションの機能を使うことなく、テストに必要な状況を作り出すことができます。テストの中で、テスト対象以外のアプリケーションコードを実行すると、何をテストするためのものなのかが、ぶれてしまうので、環境構築はフレームワークやライブラリで用意された機能のみでシンプルに実現するのが良いでしょう。
- コメント (Close): 0
- トラックバック (Close): 0
「Ansibleではじめるサーバ作業の自動化」を発表してきました
2014/10/11 に開催された PHPカンファレンス にて、「Ansibleではじめるサーバ作業の自動化」という発表を行ってきました。
![]()
午前中のセッションだったのですが、多くの方にご参加頂き、ありがとうございました。
発表資料
発表資料をslideshareに公開しました。
今回は、これからAnsibleを使ってみようという方を対象として、Ansibleの基本的な内容をメインにしました。また、実際に私自身がPHPプロジェクトで採用した際のユースケースを紹介しています。
発表後、「Ansibleをやってみます!」という意見を頂けたので、このセッションの目的は達成することができました:D
このセッションのフィードバックは、joind.in にて受けて付けています。すでにいくつか好評価を頂いていて安心していますが、もし良かったらお願いします。
https://joind.in/talk/view/12035
アプリケーションエンジニアが使う自動化ツール
セッションの最後にお話しましたが、Ansible の良さは仕組みが単純であり、豊富なモジュールがあるおかげで、適用範囲が広いということです。
構成管理はもちろんのこと、デプロイやクラウドオーケストレーション、そしてアドホックなメンテナンスなど、PHPアプリケーションの動作環境を構築して、運用していくための多くのタスクを自動化することができます。
もちろん、それぞれのタスクには特化したツールがあり、それらを使う方がより深い機能を使うことができます。ただ、別のツールを習得するには、それなりの学習コストを払う必要があります。
PHP エンジニアの中には、自分が開発したアプリケーションを動かすためにインフラも見るという人が多いと思うのですが、そういった人には、学習コストが低く、一つのツールで幅広いタスクをこなすことができる Ansible は、相性が良いように思います。
はじめは、Ansible の使い方を学習する必要はありますが、その効果を考えると、悪くない投資です。
これからAnsibleをはじめるなら
当日、時間の関係で入れられなかったのですが、これから Ansible を使う人に参考になるリンクを資料に入れています。
- Ansible Documentation Ansible 公式ドキュメントです。何度もお世話になります。Dash に docset があるので、Dash ユーザの方はそちらも便利です。
- Phansible PHP の開発環境を構築する Vagranfile を生成します。Ansible でプロビジョンを行うので、Playbook の書き方など参考になります。
- Ansible Galaxy Role が公開されいるサイトです。ansible-galaxy コマンドで取り込んでも良いですし、他の人の書き方が参考になります。
- ansible-examples Ansible 公式の Playbook サンプルです。LAMP や tomcat など様々なサンプルがあり、参考になります。
- 入門Ansible
日本語で書かれた電子書籍です。分かりやすくまとまっていて、Ansible はじめる人はまず読んでおくと良いです。
さいごに
今回は午前中の発表ということで、午後からは気楽に過ごすことができました。見たいセッション続出で右往左往したりはしましたが、いくつかのセッションを楽しむことができました。
なぜか最後の懇親会で司会したりしてましたが、来年はスタッフの中から手を上げる人が出るといいと思います!(あとやっぱり、PIO でやる懇親会は良いですね。)
今年も楽しいカンファレンスをありがとうございました。
- コメント (Close): 0
- トラックバック (Close): 0
Ansible で EC2 インスタンスを起動して、Route53 に Public DNS を登録する
Ansible は、構成管理ツールとして認知されていますが、AWS 関連のモジュールが多数実装されており、各コンポーネントの起動や設定ができます。
![]()
このエントリでは、Ansible で、検証環境用の EC2 インスタンスを起動して、その Public DNS をRoute 53 に登録してみます。
以前書いたこのエントリの内容 を Ansible で自動化するイメージですね。
準備
今回は、AWS を操作するので、Python の AWS SDK である boto をインストールしておきます。boto は、pip なり、yum なりでインストールできます。
- OSX
$ pip install boto
- RHEL / CentOS
$ rpm -ivh http://ftp.riken.jp/Linux/fedora/epel/6/i386/epel-release-6-8.noarch.rpm $ yum -y install python-boto
AWS 認証情報
AWS 認証情報を設定します。
playbook に直接記載する方法もあるのですが、ここでは、boto の設定ファイルである ~/.boto に記述をします。こうしておけば、playbook では、認証情報を指定する必要がありません。
[Credentials] aws_access_key_id = xxxxxxxxxxxxxxx aws_secret_access_key = xxxxxxxxxxxxxxx
EC2 インスタンスの起動
Ansible で EC2 インスタンスを起動するには、ec2 モジュールを使います。
AWS 関連のモジュールを使う場合、対象のインベントリが指定できない場合がある(対象のホストをこのタスクで生成するので)ので、local connection として実行します。
ec2 モジュールには、EC2 インスタンスを起動するためのパラメータを指定します。下記では、VPC で、t2.micro インスタンスを指定しています。各パラメータについては、EC2 インスタンスを起動する際は、お馴染みのものなので、値を指定していきます。あとで識別できるように Name タグに ansible1 を設定しておきます。
ここで起動したインスタンスの Public DNS を、Route 53 に登録するので、register を使って、処理結果をec2という変数に格納しておきます。
- hosts: localhost
gather_facts: no
connection: local
tasks:
- name: Create ec2 instanse
ec2:
key_name: keyA
instance_type: t2.micro
image: ami-0xxxxx
monitoring: yes
wait: yes
region: ap-northeast-1
group_id: sg-xxxxxx
vpc_subnet_id: subnet-xxxxx
assign_public_ip: yes
instance_tags:
Name: ansible1
register: ec2
Route 53 に Public DNS を CNAME に登録
あらかじめ決められた FQDN でアクセスできるように、先ほど起動したインスタンスの Public DNS を CNAME として Route 53 に登録します。
Route 53 の操作には、route53 モジュールを使います。
EC2 インスタンスの情報は、ec2.instances に格納されているので、これを利用します。下記では、ansible1.dev.example.com という FQDN に対して、ec2 の Public DNS を CNAME で割り当てています。
- name: Set Public DNS to CNAME in Route53
route53:
command: create
zone: dev.example.com
type: CNAME
value: "{{ item.public_dns_name }}"
overwrite: yes
record: ansible1.dev.example.com
ttl: 300
with_items: ec2.instances
playbook の実行
この playbook を ansible-playbook コマンドで実行します。
local connection を使うのですが、インベントリファイルが必要になるので、作成しておきます。
$ cat > hosts <EOF 127.0.0.1 EOF
では、実行してみましょう。ansible-playbook コマンドを実行すると、2 つのタスクが処理されました。
$ ansible-playbook -i hosts aws.yml
PLAY [localhost] **************************************************************
TASK: [Create ec2 instanse] ***************************************************
changed: [localhost]
TASK: [Set Public DNS to CNAME in Route53] *********************************************
changed: [localhost] => (item={......})
PLAY RECAP ********************************************************************
localhost : ok=2 changed=2 unreachable=0 failed=0
AWS の Management Console を確認すると、Name タグに ansible1 が設定されたインスタンスが生成されていました。
![]()
Route 53 を見ると、想定したいた FQDN の CNAME に EC2 インスタンスの Public DNS が設定されていました。
![]()
起動済の EC2 を破棄
EC2 インスタンスを起動して、Route 53 に登録するという流れはできました。
ただ、このままだと、この playbook を実行する度に新しいインスタンスが作成されるので、不要なインスタンスが残り続けます。そこで、今回は検証環境ということで、古いインスタンスは破棄した後に、新しいインスタンスを作るという流れにします。
起動済のインスタンスを破棄するには、稼働中のインスタンス ID を取得する必要があります。インスタンス ID はec2_factsモジュールを実行します。このモジュールは、インスタンス内で実行するので、インスタンスをインベントリファイルに追加する必要があります。
これを手で行うと、インスタンスを起動するたびにインベントリファイルを書き換えることになるので、Dynamic Inventory を利用します。Dynamic Inventory は、インベントリ情報をスクリプト等で動的に生成することができる仕組みです。これを使うことで、AWS から稼働中のインスタンス情報を取得して、各インスタンスをインベントリとして、タスクを実行することができます。
Ansible のソースコードには、稼働中の EC2 インスタンス情報を取得するスクリプト(plugins/inventory/ec2.py, plugins/inventory/ec2.ini)が含まれているので、これを利用します。
https://github.com/ansible/ansible/blob/devel/plugins/inventory/ec2.py
https://github.com/ansible/ansible/blob/devel/plugins/inventory/ec2.ini
ec2.py はインベントリを取得するスクリプトで、ec2.ini がその設定ファイルです。
まず、ec2.ini の設定を変更します。ec2.py は、デフォルトでは取得した情報をキャッシュ仕組みになっているのですが、今回は実行時に最新の情報を取得したいので、このキャッシュを無効にします。
$ vim ec2.ini cache_max_age = 300 # デフォルトは 300 秒なので、0 にする ↓ cache_max_age = 0
次に、playbook にインスタンス情報を取得するタスクを追加します。このタスクは、先頭に記述しておきます。hosts には、tag_Name_ansible1を指定しています。これは ec2.py で動的に取得したインベントリの内、タグ Name の値が ansible1 のホストを対象にするということです。このように ec2.py では稼働中の全インスタンスを利用するだけでなく、タグやインスタンスタイプなど様々な切り口でインベントリを絞り込むことができます。
---
- hosts: tag_Name_ansible1
gather_facts: no
user: root
tasks:
- ec2_facts:
つづいて、取得したインスタンス情報を使って、インスタンスを破棄します。インスタンスの破棄には ec2 モジュールを利用します。state=absentを指定することで、instance_idsで指定したインスタンスが破棄されます。
下記では、with_items で、インスタンスID を指定しているので、タグ名が ansible1 のインスタンスは全て破棄されます。
- hosts: tag_Name_ansible1
gather_facts: no
connection: local
tasks:
- name: Remove ec2 previous instances
ec2: state=absent
region=ap-northeast-1
instance_ids={{ item }}
wait=true
with_items: ansible_ec2_instance_id
完成した playbook の実行
playbook が完成しました。実行してみましょう。
-iオプションで、ec2.py を指定して、下記のように実行します。
実行すると下記の流れでタスクが実行されていきます。これで、何度実行しても起動しているインスタンスは一つのみになりました。
- タグ名=ansible1 の EC2 インスタンス情報取得
- 1 で取得した EC2 インスタンスを破棄
- EC2 インスタンス作成
- 3 で作成したインスタンスの Public DNS を Route 53 に登録
$ ansible-playbook -i ec2.py aws.yml
PLAY [tag_Name_ansible1] ******************************************************
TASK: [ec2_facts ] ************************************************************
ok: [xxx.xxx.xxx.xxx]
PLAY [tag_Name_ansible1] ******************************************************
TASK: [Remove ec2 previous instances] *****************************************
changed: [xxx.xxx.xxx.xxx] => (item=i-xxxxxx)
PLAY [localhost] **************************************************************
TASK: [Create ec2 instanse] ***************************************************
changed: [localhost]
TASK: [Set Public DNS to CNAME in Route53] *********************************************
changed: [localhost] => (item={...})
PLAY RECAP ********************************************************************
xxx.xxx.xxx.xxx : ok=2 changed=1 unreachable=0 failed=0
localhost : ok=2 changed=2 unreachable=0 failed=0
最終的な playbook は以下です。
---
- hosts: tag_Name_ansible1
gather_facts: no
user: root
tasks:
- ec2_facts:
- hosts: tag_Name_ansible1
gather_facts: no
connection: local
tasks:
- name: Remove ec2 previous instances
ec2: state=absent
region=ap-northeast-1
instance_ids={{ item }}
wait=true
with_items: ansible_ec2_instance_id
- hosts: localhost
gather_facts: no
connection: local
tasks:
- name: Create ec2 instanse
ec2:
key_name: keyA
instance_type: t2.micro
image: ami-0xxxxx
monitoring: yes
wait: yes
region: ap-northeast-1
group_id: sg-xxxxxx
vpc_subnet_id: subnet-xxxxx
assign_public_ip: yes
instance_tags:
Name: ansible1
register: ec2
- name: Set Public DNS to CNAME in Route53
route53:
command: create
zone: dev.example.com
type: CNAME
value: "{{ item.public_dns_name }}"
overwrite: yes
record: ansible1.dev.example.com
ttl: 300
with_items: ec2.instances
さいごに
Ansible で AWS を操作してみました。
インスタンス情報の取得やその情報の利用(インスタンス破棄)などは少しコツが必要ですが、それさえ分かれば、思ったとおりに動作しました。はじめは同じことを Terraform で行っていたのですが、プロビジョンには Ansible を使っていたので、どうせなら Ansible で完結させようと思い、試してみました。
このエントリでは、AWS の操作のみ行っていますが、実際は、インスタンス生成後にプロビジョンやデプロイを行う playbook を挟む形になります。こうすれば、EC2 インスタンス生成、プロビジョン、デプロイが Ansible だけで行うことができます。
- コメント (Close): 0
- トラックバック (Close): 0
[書評] CakePHPで学ぶ継続的インテグレーション
著者の @kaz_29 さんから「CakePHPで学ぶ継続的インテグレーション」を献本して頂きました。日頃から関心のある分野なので、早速読ませて頂きました。

PHP で学ぶ継続的インテグレーション
本書のタイトルは「CakePHPで学ぶ継続的インテグレーション」です。実際、本書の中では、CakePHPアプリケーションを題材に継続的インテグレーションを行う手法が解説されています。
ただ、ここで紹介されている継続的インテグレーションの手法は、CakePHP 固有のものではなく、他のフレームワークでも転用可能なものです。
勝手なお世話ですが、書籍のタイトルとしては、「PHPで学ぶ継続的インテグレーション」の方が、良かったかもしれませんね:D
分散された情報がこの一冊に
継続的インテグレーション(CI)を行うには、あるツールさえ入れておけばできるというものではなく、多くのツールを組み合わせる必要があります。
数年前、自社で CI 環境を構築した際は、Jenkins のインストールからはじまり、PHP向けのビルドタスクの組み込み、Git リポジトリの連携、自動テストの実行、結果レポートの出力、検証など、多くの手間がかかりました。一つ一つのツールについては、公式サイトのドキュメントなどで情報はあるのですが、それらを組み合わせて、自分達の開発プロセスに合うように一つのビルドプロセスとして、インテグレートするのが大変でした。
特に、PHP プロジェクトで CI を行う際に参考となる情報が少なく、Template for Jenkins Jobs for PHP Projects が、数少ないお手本というような状況でした。
本書では、こうした CI 環境を構築するのに必要なツール群について多くの解説があります。ざっと書きだしただけで、下記のようなツールに触れられています。
- Vagrant
- VirtualBox
- Chef
- CakePHP
- Jenkins
- Behat
- PHPUnit
- PHP_CodeSniffer
- PHPCPD
- PHPMD
- PHP_CodeCoverage
- phpDocumentor
- Composer
- Phing
- Capistrano
さらに加えて、CakePHP のプラグインもいくつか紹介されています。これらは、単にインストールして動かすということではなく、CI の流れで、それぞれのツールをどのように使うか、という視点で書かれています。
これまで、自分で細切れになった情報をかき集めて、ビルドプロセスを組み上げていく必要があったのですが、本書では、こうしたインテグレーションの一つの解法が記載されており、これから PHP プロジェクトで CI を行うには大いに参考になります。
すでに CI 環境を構築している場合も、それらを振り返り、改善していくための一つのパターンとして本書を参考にすることができます。
紹介されているツールを眺めてみるのも一つの面白さで、私は vagrant-chachier プラグイン をこの本を読んで使ってみようと思いました。
自分で CI 環境を作って、開発プロセスを実践
本書では、Vagrant を使って、自分の PC の中に仮想ホストを 3 つ、そして Github をアプリケーションコードのリポジトリとして利用するようになっています。
こうした環境構築では、実践する環境を作るのに手間がかかっていたのですが、Vagrant のおかげで仮想環境が楽に使えるようになったので、手軽に書籍の内容が実践できるようになりました。良い時代です。
仮想ホストは、開発環境(develp)、CI サーバ(ci)、本番環境(deploy)とそれぞれ役割が割り当てられていて、それぞれが Github のリポジトリをハブにして、アプリケーションのビルドやデプロイを行うようになっています。
全く同じ構成で良ければ、実際のプロジェクトにそのまま生かすこともできるでしょう。また、異なる構成でも CI として大まかな流れは似たものになるでしょうから、本書で得たノウハウを持って、自分のプロジェクトに CI を導入することができます。
実際に自分で手を動かして、CI 環境の構築、実践を行うことで、各ツールの役割や動きなどが実感として知ることができます。昨今は、Travis など SaaS のビルドサービスを使う場合も多いですが、自分で環境を作ってみることで、こうしたサービスもより理解が深まるのではないでしょうか。
サンプルコードの動かし方
書籍を読んで、記載されている手順を順に試すことで、CI 環境を構築することができます。はじめて、こうした環境を作るという方は、順に読み進めていくのが良いでしょう。
すでに CI 環境を利用している人は、公開されているサンプルコードを利用して環境構築を行うこともできます。私は、公開されているサンプルコードを使って、環境構築を行ないました。手順を記載しておきますので、参考まで。
事前準備
必要なツールです。以下は最低限必要になります。
- Vagrant
- vagrant-omnibus
- VirtualBox
ChefDk インストール
Berkshelf を使うために、ChefDk をインストールしました。これは、Berkshelf や Knife など Chef 関連のツール群をパッケージングしているツールで、ダウンロードして、パッケージをインストールするだけでツールを使うことができます。Berkshelf を gem で入れると、すんなり行けば良いのですが、環境によってエラーが発生したりするので、こうした手間を省くために利用しました。
OSX であれば、brew cask でインストールすることができます。
$ brew cask install chefdk
サンプルコード取得
サンプルコードは、アプリケーションと環境構築でリポジトリが分かれています。
はじめに、自分で push できるように両リポジトリを fork します。
そして、環境構築のリポジトリを cakephp_ci ディレクトリに git clone します。cakephp_ci ディレクトリに移動して、アプリケーションのコードをリポジトリから、application ディレクトリに展開します。
$ git clone 環境構築リポジトリ cakephp_ci $ cd cakephp_ci $ git clone アプリケーションリポジトリ application
Berkshelf でクックブック取得
Berkchelf でクックブックを取得します。下記は、brew cask でインストールした ChefDk に含まれる berks コマンドを利用しています。
$ /opt/chefdk/bin/berks vendor cookbooks
vagrant up で仮想マシンを起動
cakephp_ci ディレクトリには、Vagrantfile があるので、vagrant upで起動します。3 つのホストについて、起動、プロビジョンを行うので、しばらく待ちましょう。
$ vagrant up Bringing machine 'develop' up with 'virtualbox' provider... Bringing machine 'ci' up with 'virtualbox' provider... Bringing machine 'deploy' up with 'virtualbox' provider...
Composer の実行
develop にログインして、composer install を実行します。
$ vagrant ssh develop vagrant@develop: cd /var/www/application/current/app vagrant@develop: composer install
データベースの構築
各ホストにログインして、データベースとユーザを作成します。構築手順は、書籍の「4-3-2. データベースの作成」に記載があります。
vagrant@develop: mysql -uroot -ppassword GRANT ALL PRIVILEGES ON *.* TO 'webapp'@'%' identified by 'passw0rd' WITH GRANT OPTION; FLUSH PRIVILEGES; CREATE DATABASE blog default character set utf8; CREATE DATABASE test_blog default character set utf8;
データベーススキーマの構築
データベーススキーマは、CakePHP のプラグイン「CakeDC Migrations Plugin」を使って、構築します。マイグレーションファイルは、用意されているので、下記のように実行します。
vagrant@develop: cd /var/www/application/current vagrant@develop: ./app/Console/cake migrations.migration run all
これで、delvelop ホストで、フィーチャのテストとユニットテストが通るようになります。
vagrant@develop: cd /var/www/application/current vagrant@develop: ./app/Console/cake Bdd.story vagrant@develop: ./app/Console/cake test app
さいごに
継続的インテグレーションの環境を構築して運用していくには、それなりにノウハウが必要です。これまで自力で何とかするしかなかったのですが、本書があれば、まずベーシックな構成については、構築することができます。正直、これから CI 環境を構築する人は、羨ましいです:D
できれば、データベースの構築などもプロビジョンで行うようになっていると、より自動化できて良いと思いましたが、これは読者への課題ということなのでしょう。
また、PHPCPD や PHPMD で算出される数値をベースにコードを改善していく内容がもっとあると嬉しかったです。(やや本書の範囲からはずれていきますが)
読んでいくにあたっては、その内容がどのホストで実行すべきものなのかをイメージしながら進むようにしましょう。これは実際の現場でも同じで、このタスクはどこでやるべきことなのかは常に意識する必要があります。
CI を実践するにあたって必要な情報が、ぎゅっと、まとまった 1 冊です。CakePHP に限らず、PHP プロジェクトで継続的インテグレーションを行うなら、ぜひ一度手にとってみて下さい。
「CakePHPで学ぶ継続的インテグレーション」ハンズオン
2014/11/01 に大阪で本書を題材にしたハンズオンが開催されます。講師には、著者の @kaz_29 さんにお願いしています。私もヘルプで入るつもりなので、みんなで CI を体験してみましょう。
- コメント (Close): 0
- トラックバック (Close): 0
Vagrant のプロビジョン時間を削減する vagrant-cachier プラグインが良い
- 2014-09-27 (土)
- Vagrant
Vagrant でプロビジョンを行う際に時間がかかるのが、yum などを使ったパッケージのインストールです。ネットワーク環境が悪い場合、ダウンロード自体に時間がかかるため、大きな待ち時間が発生します。

vagrant-cachier プラグインを使うことで、このダウンロード時間を削減することができます。
vagrant-cachier プラグイン
vagrant-cachier プラグインは、プロビジョンなどでダウンロードしたパッケージをキャッシュしておくことで、次回以降のダウンロード時間を削減しようというプラグインです。
https://github.com/fgrehm/vagrant-cachier
vagrant-cachier プラグインの効果
これは効果を見たほうが早いと思うで、vagrant-cachier プラグインを導入した場合の効果についてです。
vagrant destroy で VM を破棄した後に、vagrant up を実行して、その実行時間を time コマンドで計測しています。
$ vagrant destroy -f $ time vagrant up
今回、計測に利用した Vagrantfile は、ある PHP プロジェクトで利用しているものです。Ansible によるプロビジョン(VM内で実行)を行っており、Composer の実行や PHPUnit による自動テストも行っています。これらは本プラグインとは無関係なのですが、実際に使う場面で効果があるか見たかったので、この環境で計測しています。
- プラグインなし
比較のために vagrant-cachier プラグインを入れていない状態で、vagrant up を実行した結果です。
vagrant up 4.64s user 2.19s system 0% cpu 11:36.15 total
- プラグインインストール済み(初回)
vagrant-cachier インストールして、初回(キャッシュが無い状態)の実行時間です。
vagrant up 6.18s user 2.69s system 1% cpu 12:33.26 total
- プラグインインストール済み(2回目)
vagrant-cachier インストール後、キャッシュがある状態での実行時間です。
vagrant up 6.26s user 2.68s system 2% cpu 6:42.31 total
- 結果
結果を表にまとめたのが以下です。実行時間を比較してみると、プラグインをインストールして、キャッシュがある状態なら、実行時間が約半分になりました。これは大きな効果ですね。
| 実行時間 | |
|---|---|
| プラグイン無し | 11.36.15 |
| プラグイン有り(キャッシュ無し) | 12.33.26 |
| プラグイン有り(キャッシュ有り) | 6.42.31 |
インストール
vagrant-cachier プラグインをインストールするには、vagrant plugin install コマンドを実行するだけです。
$ vagrant plugin install vagrant-cachier
Vagrantfile への記述
vagrant-cachier プラグインを有効にするには、Vagrantfile に下記の設定を行います。config.cache.scope では、キャッシュスコープを設定します。
下記では、:boxを指定しており、これは、プロビジョンでインストールしたパッケージを Box 単位でキャシュします。同一 Box を使う Vagrantfile であれば、別の VM でもキャッシュを共有することができます。
私の用途であれば、この設定が使いやすそうです。
あとは、通常どおり、vagrant up を行うとプラグインが有効となり、キャッシュを行うようになります。
Vagrant.configure("2") do |config|
# (snip)
if Vagrant.has_plugin?("vagrant-cachier")
config.cache.scope = :box
end
# (snip)
end
その他のキャッシュスコープやオプションついては、vagrant-cachier のサイトを参照にして下さい。
http://fgrehm.viewdocs.io/vagrant-cachier/usage
何をキャッシュしているのか
プロビジョンで追加したパッケージをどうやってキャッシュしているのか気になったので、仕組みを見てみました。
コードを見たところ、CentOS の場合は、ゲストの /var/cache/yum が /tmp/vagrant-cache/yum へのシンボリックリンクになっています。そして、この /tmp/vagrant-cache/ は、ホスト側との synced_folder となっており、~/.vagrant.d/cache/BOX_NAME/ がマウントされています。
つまり、ゲストで yum install コマンドでインストールすると、/var/cache/yum にパッケージのキャッシュファイルが保存されます。これは、ホストの ~/.vagrant.d/cache/BOX_NAME/yum と synced_folder で同期しているので、結果としてホストにこのキャッシュファイルが保存されます。
これは、なかなか面白い仕組みですね。
さいごに
vagrant-cachier プラグインを使うことで、プロビジョンの実行速度が大きく改善されます。プロビジョンコードを書くと、検証のために何度もプロビジョンを実行することになり、その度に待たされていました。このプラグインを使うことで、その時間が削減できるので、プロビジョンが捗ります。
ちなみに、このプラグインは、CakePHPで学ぶ継続的インテグレーション を読んで、知りました。
いま読み進めているところですが、PHP で CI したい人には嬉しい内容になっています。書評は、また別エントリで書きますね。
- コメント (Close): 0
- トラックバック (Close): 0
Ansible で、複数サーバの RPM を一括で更新する
- 2014-09-25 (木)
- Ansible
Bash 脆弱性が出ましたね。対策がまだの方はお早めに。
![]()
修正 RPM が提供されているとはいえ、複数サーバにログインして、yum update していくのは、骨が折れる作業です。元から構成管理ツールを導入していて、一括更新出来る場合は良いのですが、なかなか導入できていないところも多いでしょう。
このエントリでは、Ansible を使って、複数サーバに対して、一括で RPM 更新を行う方法を見ていきます。
Ansible インストール
Ansible の操作を行う PC or サーバにインストールします。これは ansible コマンドを実行する環境にのみインストールします。例えば、サーバ管理者の PC などです。チームで行う場合は、操作用のサーバにインストールして、SSH で操作サーバにログインして、実行すると良いでしょう。
OSX なら、Homebrew で入れるのが簡単です。
$ brew install ansible
RHEL / CentOS なら、EPEL で配布されているので、yum でインストールできます。
$ rpm -ivh http://ftp.riken.jp/Linux/fedora/epel/6/i386/epel-release-6-8.noarch.rpm $ yum -y install ansible
インストールが完了したら、ansible コマンドが動作するか確認しておきます。
$ ansible --version ansible 1.7.1
対象ホスト
対象ホストは、SSH でログインができれば、別途インストールは不要です。(実際は、Python がインストールされている必要があるのですが、多くの Linux 環境ではインストールされています。)
あと、リモートホスト上で実行したい操作に root 権限が必要な場合(RPM の更新には必要)は、root ユーザでログインするか、SSH ログインするユーザが sudo できる状態にしておく必要があります。
対象ホストをインベントリファイルに記述
処理対象のホストを指定するためにインベントリファイルを作成します。インベントリファイルには、対象サーバのホスト名や接続情報を記述します。
下記では、host1.exmaple.com と host2.example.com を処理対象のホストとして指定しています。
$ vim hosts host1.example.com host2.example.com
インベントリファイルでは、SSH接続情報をパラメータとして指定することができます。良く使うパラメータは以下です。
- ansible_ssh_port = SSH接続ポート(22 以外を使う場合に指定)
- ansible_ssh_user = SSH接続ユーザ名(指定が無ければ、ansible コマンドを実行したユーザ)
- ansible_ssh_pass = SSH接続パスワード(パスワード認証の場合。パスワードを書くのは好ましくないので、–ask-pass をオプションを指定した方が良い)
- ansible_ssh_private_key_file = 公開鍵認証時の秘密鍵ファイルパス
インベントリファイルでは、下記のように指定します。
host1.example.com ansible_ssh_user=user1 ansible_ssh_private_key_file=/path/to/secret_key host2.example.com ansible_ssh_user=ec2-user
ホストをグループ化(ロールやプロジェクト等)したい場合、インベントリファイルを分ける(projectA_hosts, projectB_hosts)か、グループを指定することができます。
イベントリファイルでグループを指定する場合は、下記のように記述します。
[groupA] host1 host2 [groupB] host3
ansible コマンドの実行
ansible コマンドを実行してみましょう。
ansible コマンドを使って、リモートホストでコマンドを実行する場合、下記のようにオプションを指定します。
$ ansible 処理対象ホスト -i イベントリファイル -m shell -a "コマンド"
ansible コマンドに続いて、処理対象のホストを指定します。これはイベントリファイルに含まれている必要があります。全てのホストを対象とする場合は、allを指定します。グループ内のホストを対象をする場合は、グループ名を指定します。
-i オプションでイベントリファイルを指定します。
そして、実行するモジュールを指定します。ここでは、shell モジュールを使って、コマンドをリモートホストで実行したいので、-m shell -a オプションを指定します。
下記が実行例です。ここでは、hosts に書かれた全てのホスト上で、uname -a コマンドを実行します。それぞれのホストでの実行結果が表示されており、コマンドが実行できたことが確認できます。
$ ansible all -i hosts -m shell -a "uname -a" host1.example.com | success | rc=0 >> Linux host1.example.com 2.6.32-431.11.2.el6.x86_64 #1 SMP Tue Mar 25 19:59:55 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux host2.example.com | success | rc=0 >> Linux host2.example.com 2.6.32-431.11.2.el6.x86_64 #1 SMP Tue Mar 25 19:59:55 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
ansible コマンドには、shell モジュール以外にも多くの機能があるのですが、ここではこのモジュールのみ利用します。
RPM のバージョン確認
では、実際に RPM の更新を ansible コマンドで実行してみましょう。ここでは、対象 RPM を bash とします。
まずは現在の RPM のバージョンを確認しておきます。もちろん、これにも ansible コマンドを使います。RPM のバージョン確認には、rpm -qv コマンドを使います。
実行結果が以下です。それぞれの bash のバージョンが表示されています。host1 は、現段階(2014/09/25)での最新版となっていますが、host2は、まだ古いままとなっています。
$ ansible all -i hosts -m shell -a "rpm -qv bash" host1.example.com | success | rc=0 >> bash-4.1.2-15.el6_5.1.x86_64 host2.example.com | success | rc=0 >> bash-4.1.2-15.el6_4.x86_64
ansible で RPM を更新
RPM の更新を行ないます。
RPM の更新では、yum -y update bash コマンドで行ないます。通常、yum updateすると Yes or No の確認が入るのですが、ここでは自動実行するので、-y オプションを付けておきます。
では実行してみましょう。
$ ansible host1.example.com -i hosts -m shell -a "yum -y update bash" host1.example.com | success | rc=1 >> Loaded plugins: downloadonly, fastestmirror, securityYou need to be root to perform this command.
おっと、エラーが発生しました。yum update では、root 権限が必要なためです。では、--sudoオプションを付けて、再実行してみましょう。
次は、無事に更新することができました。
$ ansible host1.example.com -i hosts --sudo -m shell -a "yum -y update bash" host1.example.com | success | rc=0 >> Loaded plugins: fastestmirror Loading mirror speeds from cached hostfile (snip) Updated: bash.x86_64 0:4.1.2-15.el6_5.1 Complete!
念のため、バージョンを確認しておきます。両ホスト共に最新版となりました。
$ ansible all -i hosts -m shell -a "rpm -qv bash" host1.example.com | success | rc=0 >> bash-4.1.2-15.el6_5.1.x86_64 host2.example.com | success | rc=0 >> bash-4.1.2-15.el6_5.1.x86_64
さいごに
Ansible で、複数ホストの RPM を更新してみました。
本文で見てきたように、Ansible は、SSH ログインができるリモートホストなら、エージェントなどをインストールしなくても利用できるのが利点の一つです。ツールによる構成管理ができていない環境でも、操作用の環境にさえ Ansible をインストールすれば気軽に使いはじめることができます。
OpenSSL に続き、今回の Bash 脆弱性発覚、もちろん RPM 更新以外にもサーバ運用では何かと一括で操作を行うタスクが発生します。
Ansible を活用して、こうしたタスクの手間を削減してみてはどうでしょう。
なお、Ansible には、今回紹介したスポットでのコマンド実行の他にも、構成管理やデプロイなど、サーバ構築や運用のタスクを自動化する機能があります。10/11 に開催される PHP カンファレンスでは、そのあたりをお話したいと思いますので、ぜひご参加下さい:D
http://phpcon.php.gr.jp/w/2014/
参考
Ansible Documentation
Ansible チュートリアル | Ansible Tutorial in Japanese
- コメント (Close): 0
- トラックバック (Close): 0
PhpStorm 8 で、Vagrant VM の PHPUnit を IDE から実行する
PhpStorm 8 が、リリースされましたね!
PHP 5.6 や Laraevel の blade 対応など気になる新機能があるのですが、その中でも、注目なのが、PHPUnit by Remote Interpreter です。
この機能を使うことで、Vagrant VM にインストールされている phpunit をホストの PhpStorm から直接実行することができます。Vagrant による開発が普及してきた今では必須の機能といえるでしょう。
利用するには、いくつか設定が必要となるので、その手順を書いてみます。
対象の PHP アプリケーション
このエントリでは、以下の環境で PHP アプリケーション開発しているという想定で進めていきます。
- Vagrant VM で PHP アプリケーションを実行
- PHPUnit は、Composer でインストール
- PHPUnit の設定は、phpunit.xml に記述
PHP Interpreter の設定
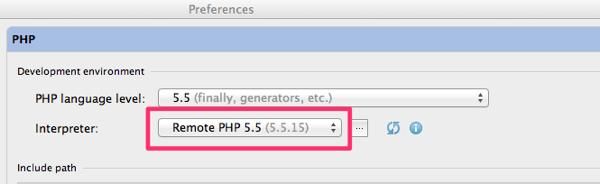
はじめに PHP Interpreter に Vagrant VM の php を指定します。
Preferences – PHP を開いて、Interpreter プルダウンメニュー横にある ... をクリックします。
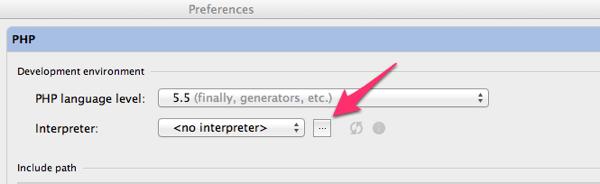
クリックすると Interpreters ダイアログが表示されます。まず、左上にある + をクリックして、Remote...を選択します。
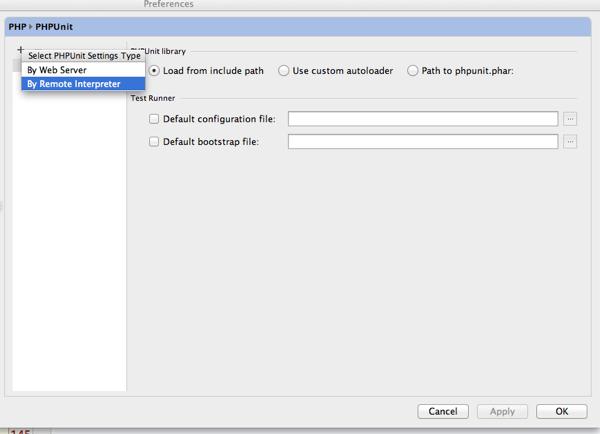
Configure Remote PHP Interpreter ダイアログが表示されるので、Vagrant を選択します。選択すると、Vagrant 用の入力フォームに表示が変わり、各フォームに自動で値が入ります。ここでは編集せずに進みます。もし必要があれば変更して下さい。
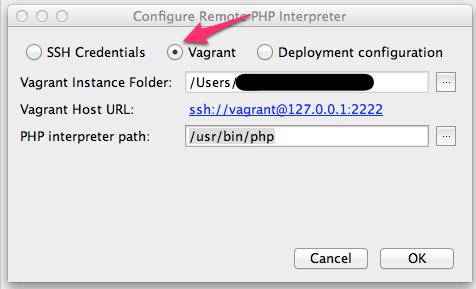
OKを押すと、Vagrant VM と通信して、設定項目が妥当か検証が行われます。問題無ければ、ダイアログが閉じます。
Interpreter ダイアログの左側ツリーには、追加したRemote PHP 5.5が表示されます。右側フォームの General には、Vagrant VM にインストールされている PHP と Xdebug のバージョンが表示されるので、念のため確認しておくと良いでしょう。
OKを押して、ダイアログを閉じます。
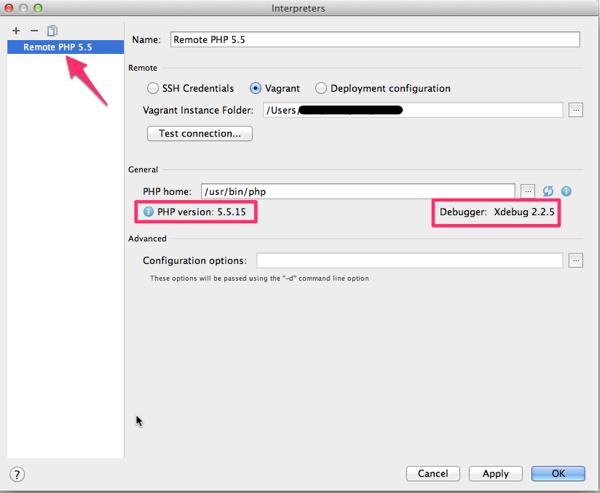
PHP に戻ると、設定した Interpreter が選択されています。OKをクリックして、PHP Interpreter の設定は完了です。
PHPUnit By Remote Interpreter の設定
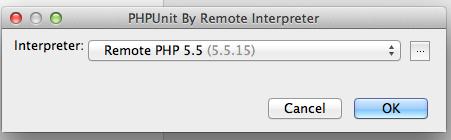
次に PHPUnit の設定を行ないます。Preferences – Project Settings – PHP – PHPUnit を開きます。
PHPUnit ダイアログの左上に + があるので、これをクリックして、By Remote interpreterを選択します。
PHPUnit By Remote Interpreter ダイアログが開きます。Interpreter に先ほど登録したRemote PHP 5.5を選択して、OK をクリックします。
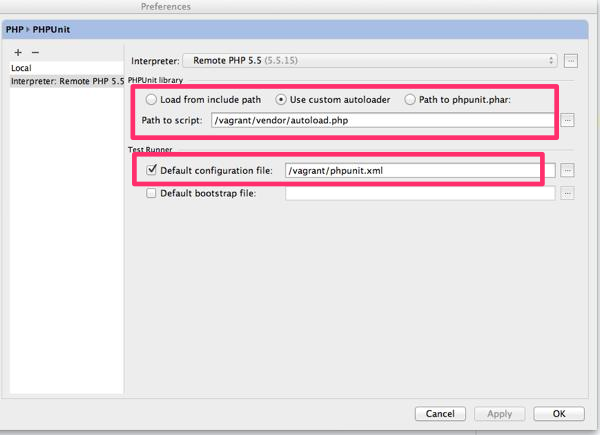
ダイアログが閉じると、右側に PHPUnit の設定項目が表示されます。
PHPUnit 関連のファイルは、Composer のオートローダーから読み込むので、PHPUnit library には、Use custom autoloader を選択します。Path to script が表示されるので、Composer の autoload.php のパスを設定します。なお、この設定は VM 内でのパスを指定する必要があるので注意して下さい。(テキストボックス横の ... をクリックすると、VM 内のパスを GUI で指定することができます。)
次に、Test Runner の Default configuration file にチェックを入れて、phpunit.xml のパスを指定します。(phpunit.xml を利用していない場合、これは不要です。)ここのパスも VM 上のパスになります。
設定が完了したら、Apply もしくは OK をクリックします。これで、PHPUnit By Remote Interpreter の設定は完了です。
Run/Debug Condigurations での PHPUnit 設定
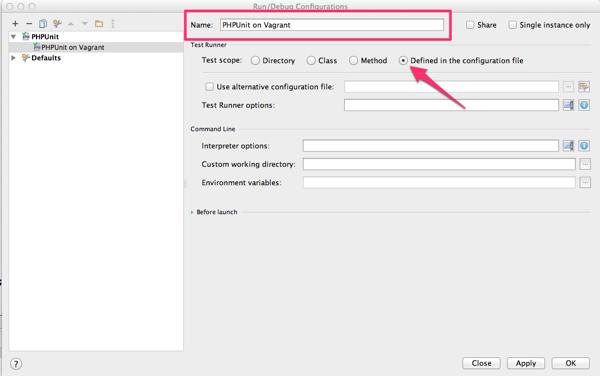
最後に、IDE からテストを実行するために、Run/Debug Configurations にて PHPUnit の設定を行ないます。
画面左上にある + をクリックして、PHPUnitを選択します。(PHPUnit on Server ではないので、注意して下さい。)
Name には、それと分かる名称を記述します。ここでは PHPUnit on Vagrantとします。
次に、Test Runner の Test scope を選択します。ここでは、前項で phpunit.xml へのパスを指定しているので、Defined in the configuraion fileを指定します。(テストディレクトリを指定したい場合は、Directoryを選択して、対象のディレクトリを記述して下さい。)
OKをクリックして、設定は完了です。
PHPUnit の実行
いま設定した PHPUnit を実行してみます。ウィンドウメニューバー右上にて、下記のように設定したPHPUnit on Vagrantを選択した状態で、右側の矢印をクリックするとテストが実行されます。( Run を実行すれば良いので、メニューから選択しても、CTRL + R でも良いです。)
テストが実行できました!
IDE から Vagrant VM の PHPUnit を実行する良さ
実際に使ってみて良かった点です。
1. 操作が楽
これまでテストを実行する時は、ターミナルアプリケーション に遷移して、phpunit コマンドを実行していました。それが、PhpStorm 内で CTRL + R だけで実行できるようになりました。ちょっとした手間ですが、同じウィンドウで済ませられるので楽です。
2. diff が見やすい
アサーションでテストが失敗した時に、期待した値と実際の値と差分を表示することができます。この差分表示は、コードの変更差分と同じ形式で、左に期待した値、右に実際の値を表示してくれます。これは phpunit コマンドの実行結果に比べて、分かりやすいです。
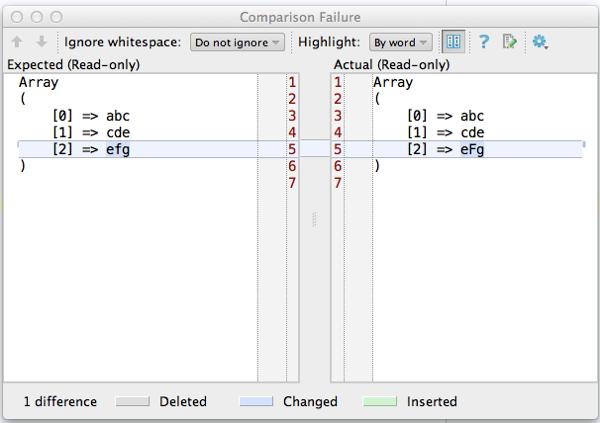
3. 各テストの実行時間が分かる
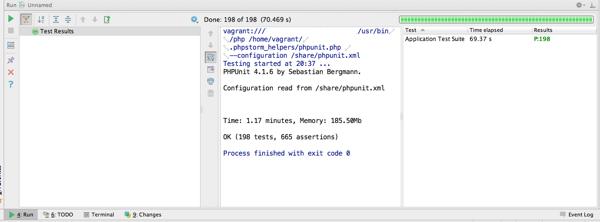
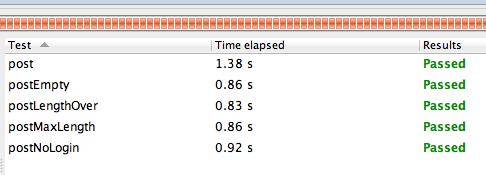
テスト全体の実行時間だけでなく、各テストケースの実行時間も記録されているので、一覧で確認することができます。もちろん、実行時間で並べ替えもできるので、遅いテストの確認なども簡単です。
さいごに
PHPStorm 8 の PHPUnit By Remote Interpreter を使って、PhpStorm から Vagrant VM にある PHPUnit を実行してみました。
上でも書きましたが、設定して、開発サイクルでテストを実行すると、想像していた以上に楽です。テストの実行が気軽にできますし、結果も分かりやすいです。
Vagrant を使って、PHP アプリケーションを開発しているなら、ぜひ設定してみて下さい。
参考
- コメント (Close): 0
- トラックバック (Close): 0
PHP コードの整形はプログラマがやるべきことじゃない
PHP には、PSR が策定されたおかげで、これをベースにコーディングスタイルがある程度整ってきました。
ここ近年開発がはじまったプロジェクトなら、PSR-1/2 をコーディングスタイルとして採用しているプロジェクトも多いのではないでしょうか。
せっかく採用したなら、実際に書くコードはできるだけこの基準に沿うようにしたいものです。ただ、ここにあまり手間をかけるのも本末転倒です。そこで、手間をかけずに、コーディングスタイルに従えるような方法を模索してみました。
開発環境には、PhpStorm を使う前提です。
PhpStorm の PSR1/PSR2 ルール
まず、PhpStorm の Code Style で、PSR1/PSR2 をルールとして設定しました。
プロジェクト毎に規定したいので、Scheme はProjectにして、set from...をクリックして、Predefined Style から PSR1/PSR2を選択します。
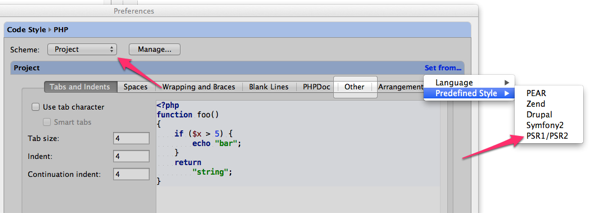
これで、PSR-1/2 のルールがコーディングスタイルへ設定されます。
コーディングスタイルによるコード整形(Reformat)
PHP コードを書いていけば、インデントやブレース位置など自動で適用してくれます。
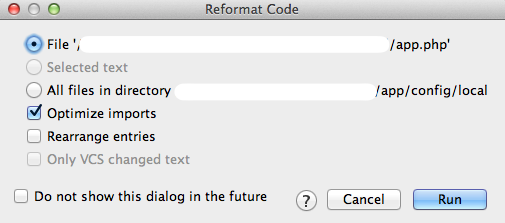
また、フレームワークで自動生成されたコードなど既存のコードに対して、整形する機能があります。それが Reformat Codeという機能です。
Search Everywhere(⌘ ⌘)から、「reformat」と入力して、選択しても良いですし、⌘ + option + enter でも ok です。
Reformat Codeを実行すると、下記のようなダイアログが表示されます。適用範囲の選択やオプションが選択できます。Optimize importsにチェックを入れておくと不要な import文を削除してくれたりすので、チェックしておくと良いでしょう。Rearrenge entriesにチェックを入れると、メソッドの順序を並べ替えたりするので、これは外しておきます。
Runを実行するとコーディングスタイルに従って、コードが整形されます。
例えば、下記のようなコードがあるとします。
class Foo{
public function hello($show=false) { if($show){print "Hello".PHP_EOL;}
}
}
これを Reformat Code すると、以下のように整形されます。
<?php
class Foo
{
public function hello($show = false)
{
if ($show) {
print "Hello" . PHP_EOL;
}
}
}
Reformat Code は、単一ファイルだけでなく、特定のディレクトリ以下の全てのファイルに対して行うこともできるので、一括で整形するのも簡単です。
PhpStorm PSR1/2 スタイルへの違和感
設定も簡単で良かったのですが、Reformat Code でコード整形すると、これだけは気になるというコードがあります。
それは、クロージャをメソッドの引数に渡すコードです。
例えば、下記のようなコードがあります。
Route::post('/', function() {
return View::make('index');
});
これを Reformat Code すると、下記のようになります。
Route::post(
'/',
function () {
return View::make('index');
}
);
うううん、これは気持ち悪い。。。Reformat する前の方が読みやすいし、行数も少なくて済みます。
コード整形のルールは、Code Styleの設定次第なので、該当箇所を特定して変更していました。
環境毎にいちいち設定?
日頃 iMac と MBA を使って開発しているので、PhpStorm はそれぞれの PC にインストールしています。設定は共有していないので、こうしたカスタマイズを行うと、それぞれに適用する必要があります。
また、PhpStorm は、時折うっかり設定を忘れてしまうようで、たまに再設定を行ったりします。
そして、チームで開発する際は、メンバーがそれぞれ該当箇所を設定するする必要があります。(チームメンバーで設定を共有するような仕組みが PhpStorm にあれば、良いのですが、まあそれは未来に期待して。)
設定自体はそれほど大変ではないですが、全ての環境で行うには手間がかかります。
PHP Coding Standards Fixer
じゃあ、PHP Coding Standards Fixer で、自動変換すれば良いじゃないかと思い、.git/hooks/pre-commitに仕込んだりしたのですが、これもそれぞれの環境で仕込む必要があり、それもまた手間です。
ちなみに、以下のような設定を書いてました。これは自動変換ではなく、コーディングスタイルに合致しないコードがあれば、警告を出して commit を reject する仕様になってます。
#!/bin/sh
#
# An example hook script to verify what is about to be committed.
# Called by "git commit" with no arguments. The hook should
# exit with non-zero status after issuing an appropriate message if
# it wants to stop the commit.
#
# To enable this hook, rename this file to "pre-commit".
#
# php-cs-fixer
#
PROJECTROOT=`echo $(cd ${0%/*}/../../ && pwd -P)`/
FIXER=php-cs-fixer.phar
if [ ! -e ${PROJECTROOT}${FIXER} ]; then
echo "PHP-CS-Fixer not available, downloading to ${PROJECTROOT}${FIXER}..."
curl -s http://cs.sensiolabs.org/get/$FIXER > ${PROJECTROOT}${FIXER}
echo "Done. First time to check the Coding Standards."
echo ""
fi
DIRECTORIES="app bootstrap public package"
for d in ${DIRECTORIES}; do
php ${PROJECTROOT}${FIXER} fix $PROJECTROOT/src/${d} --verbose --dry-run --fixers=indentation,linefeed,trailing_spaces,unused_use,short_tag,visibility,php_closing_tag,braces,extra_empty_lines,include,controls_spaces,elseif,eof_ending,function_declaration
if [ $? -ne 0 ]; then
exit 1
fi
done
もう、PSR1/PSR2 そのままで良いんじゃないか
しばらく悶々としながら開発していたのですが、もう人間の好みは捨てて、ツールに委ねる方が良いのでは、という考えに至りました。
PhpStorm デフォルトの PSR1/PSR2 を適用すれば、かなりの部分は読みやすいコードに整形してくれます。クロージャの部分も読みにくいというより、好みではない(なんとなく気持ち悪い)という程度なので、これは慣れれば、どうということはなさそうです。
結果として、PhpStorm の PSR1/PSR2 をカスタマイズせず、そのままコーディングスタイルとして利用するようになりました。
コーディングスタイルを自動で適用
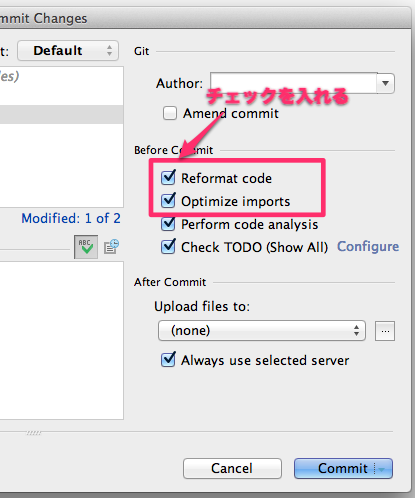
せっかくのコーディングスタイルですが、毎回、手で Reformat Code を実行するのは手間です。そこで、commit 時に自動で適用するようにしています。
Commit を実行した際に表示されるダイアログの右にある Before Commit の Reformat codeとOptimize importsにチェックを入れておけば、commit 前にこれらを自動実行して、整形済のコードを commit してくれます。
さいごに
本文でも書いたように、現在は、PhpStorm 標準のPSR1/PSR2ルールを利用しており、commit 時に自動で整形されるようにしています。IDE やエディタが複数混在していたり、人数が多くなると、CI などで一括管理した方が良いかもしれませんが、設定の手間と効果を考えると、今のところ、この運用で十分です。
PhpStorm の Reformat Code はなかなか良くできており、多少の好みくらいならカスタマイズせずに、ツールに寄り掛かる方が良いと実感しました。将来フォーマットが変わるかもしれませんが、それはそれで自動整形すれば良いだけです。
これだけツールが良くなると、コーディングスタイルを人間が気にすること自体が無駄な気がしてきて、ツールが勝手に決められたルールに従って整形してくれれば、それで良いという考えになってきました。
ちなみに、件のクロージャのスタイルは時間が経つにしたがって、気にならなくなってきました。引数が多い場面などは、かえってこの方が読みやすいんじゃないかという気さえしてきたので、まあ慣れの問題ですね。
- コメント (Close): 0
- トラックバック (Close): 0
Laravel 4 環境ごとの設定
Laravel には、アプリケーションの設定を環境によって切り替える機構があります。これを使うことで、開発環境、ステージング環境、本番環境、テスト環境で設定を切り替えることができます。
ここでは、Laravel 4.2 を対象とします。
環境設定の指定
環境設定の指定は、bootstrap/start.php の以下の箇所で行ないます。デフォルトでは、ホスト名がhomesteadの場合はlocal、それ以外はproductionとなります。
$env = $app->detectEnvironment(array(
'local' => array('homestead'),
));
このdetectEnvironmentメソッドでは、クロージャが引数の場合、その戻り値を環境設定として扱うことができます。
私は、環境変数での切替の方が扱いやすいので、LARAVEL_ENVという環境変数の値を取得して、それを環境設定としています。環境変数に指定が無ければ、localをデフォルトの設定としています。
$env = $app->detectEnvironment(function () {
if (getenv('LARAVEL_ENV')) {
return getenv('LARAVEL_ENV');
}
return 'local';
});
環境変数であれば、Web サーバの設定なり、シェルの設定なり、アプリケーションの外から渡すことが容易なので、柔軟に設定を切り替えることができます。
例えば、あるプロジェクトでは、本番へのデプロイ時に.htaccessを動的に生成して、その中でSetEnv LARAVEL_ENV productionを記述するタスクを自動実行するようにしています。また、Heroku 環境では、アプリケーションに環境変数が設定できるので、そこでLARAVEL_ENV=herokuを設定しています。
環境ごとの設定
環境ごとの設定は、設定ファイルのディレクトリを作成することで指定することができます。
まず、メインとなるのが、app/config/以下の設定です。ここに上記で指定した環境設定をディレクトリとして作成して、その下に設定ファイルを設置すると、それが読み込まれます。
app/config/
+ local/ <--- local 用設定
+ app.php
...
+ production/ <--- production 用設定
+ app.php
...
+ heroku/ <--- heroku 用設定
+ app.php
...
設定は、まず、デフォルト(app/config/直下)の各ファイルが読み込まれ、環境ごとのディレクトリにある設定ファイルの内容がそれに上書かれるという動作になります。よって、環境ごとのディレクトリには、デフォルトから変更の必要があるファイルのみ設置します。また、設置したファイルでも全ての要素を記述する必要はなく、変更が必要なもののみ記述します。
例えば、app/config/app.php はデフォルトのままの場合、app/config/local/app.php では下記のように記述します。
この設定では、app.phpの debug と provider について変更を行っています。debug は true に変更しています。providersでは、デフォルトの値は全て有効にして、追加のみ行ないたいので、append_config関数で追加する ServiceProvider のみ指定しています。
このように変更差分にのみ記述することで、最小限の記述で環境ごとに設定値を変えることができます。
<?php
return [
'debug' => true,
'providers' => append_config([
'BarryvdhLaravelIdeHelperIdeHelperServiceProvider',
'WayGeneratorsGeneratorsServiceProvider',
]),
];
利用している環境設定
よく利用している環境設定は以下です。
- local = Vagrant VM 開発環境用。
debug=true、IdeHelper や Generator など開発用 ServiceProvider を組み込む。 - production = 本番環境用。
debug=falseで、開発用 ServiceProvider は除外。暗号キーは、専用のものに。 - statging = ステージング環境用。ほぼ本番環境で、
urlなどを変更。 - heroku = Heroku環境用。Heroku では、各種アドオンとの接続情報を環境変数から得るので、そのあたりを各設定ファイルに記述。
- testing = 自動テスト環境用。テスト用データベース設定など。これはフレームワークで予約されており、テスト実行時には自動で指定される。
artisan コマンド
artisan コマンドでも同じフローで環境が決定されるのですが、それとは別に--envオプションで指定することができます。
下記のように local 環境においても、--env=productionを指定すると production 環境で実行することができます。
$ php artisan env Current application environment: local $ php artisan env --env=producion Current application environment: producion
さいごに
Laravel の環境設定について見てみました。
多様な環境について設定を切り替える機構は便利なもので、とても重宝しています。
いまは環境変数での指定に落ち着いていますが、staging などで、artisan コマンド実行時に--envを指定する手間を省くために、.laravel_envのような環境を指定するファイルを用意して、そこに環境設定を記述して、それを読み込むというようなことも考えています。(.laravel_env は .gitignore して、デプロイ時に自動生成する想定。)
.laravel_envがあればそれを使い、無ければ環境変数から読むという流れです。
どのように環境を決定するかということも、アプリケーションで柔軟に変更できるというのも良くできているところですね。
参考
- コメント (Close): 0
- トラックバック (Close): 0
AWS EC2 インスタンス間の名前解決に Route 53 を使う
- 2014-09-05 (金)
- AWS
Route 53 に EC2 インスタンスの Public DNS を CNAME で登録して、それを EC2 インスタンス間での通信でも利用するという話です。
1. 前提
- EC2-Classic 環境
- EC2 インスタンスの接続情報(FQDN なり IP なり)は、AWS のメンテナンスによる再起動などで変更される。
- アプリケーションやミドルウェアで、別インスタンスに接続している場合、AWS から割り当てられる Public DNS や IP を設定ファイルなどに記述していると、変更の度に修正が必要になる。
- DNSサーバを立てようとしたが、そこまで変更の頻度は多くない(日常的にインスタンス数が増減するわけではない)ので、正直わざわざ立てるほどでも無い。また、DNS サーバの面倒も見たくない。
2. やりたいこと
- Route 53 で各ホストの接続情報を管理すれば、一元管理できるし、修正も一箇所で済む。
- DNS サーバの面倒を見る必要が無いし、自分で運用するより安心。(Route53 は、SLA 100%)
- EC2 インスタンスごとに FQDN を割り当てて、CNAME として EC2 インスタンスの Public DNS を設定する。
- Public DNS を設定するのは、同じ FQDN で、AWS 外部からはグローバル IP、内部ではプライベート IP を返せるようにするため。
- 外部からのアクセスは、Security Group で制限する。
3. 設定
3-1. Route 53 で、サブドメインを作る
まず、EC2 インスタンス用のサブドメインを作成します。これは FQDN の管理の都合上だけなので、すでに存在してるドメインに、CNAME レコードを追加しても問題無いです。
ここでは、example.com を保持しているとして、サブドメインとして aws.example.com を作成します。EC2 インスタンスは、web1.aws.example.com や db-master.aws.example.com などにします。
まず、Route 53 の画面で、「Create Hosted Zone」をクリックして、新しいゾーンを作成します。Domain Nameには今回作成するサブドメインを記述します。
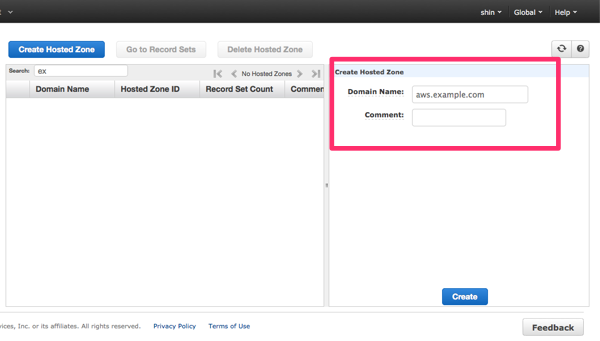
ゾーンを作成すると、Delegation Set が割り当てられます。これは後で、委譲先として設定するのでコピーしておきます。
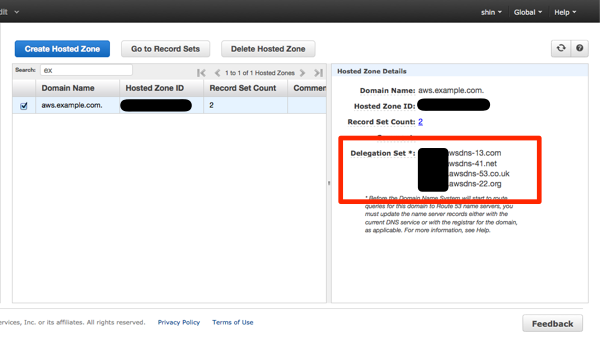
aws.example.com をサブドメインとして設定します。ここでは、example.com ドメインを Route 53 で管理している想定なので、それ以外の場合は、それぞれ適時設定して下さい。
すでにある exaple.com ゾーンを開いて、「Create Record Set」をクリックして、新しいレコードセットを作成します。画面右側のフォームで、「Name に aws を、Type に NS - Name server を入力します。Value には、先ほどコピーしておいた aws.example.com ゾーンの Delegation Set の内容をペーストします。
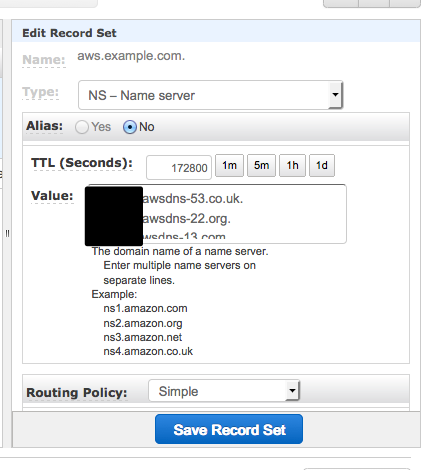
これで aws.example.com の設定ができました。
3-2. Route 53 で、EC2 インスタンスの FQDN を設定する
あとは、作成した aws.example.com に、レコードセットを追加して、EC2 インスタンスの Public DNS を CNAME として登録していくだけです。
ここでは、Web サーバとして使っている EC2 インスタンスの Public DNS を、web1.aws.example.com に割り当てます。
まず、EC2 の Public DNS を確認します。Management Console では下記のように表示されているので、これをコピーしておきます。

次に、Route 53 で、aws.example.com ゾーンを選択して、「Create Record Set」をクリックします。フォームには、以下のように、Name に web1、Type に CANE - Canonical name、Value に先ほどコピーした EC2 インスタンスの Public DNS を設定します。
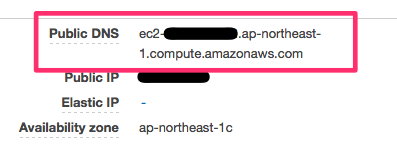
これで設定は完了です。
3-3. 動作確認
設定した FQDN が引けるかどうか確認します。(実際は、実在の FQDN で実行してますが、ここでは例示のため、exmaple.com ドメインとしています。)
まず、EC2 インスタンス内で引いてみます。こちらでは、10.0.yyy.yyy というローカル IP が引けました。
[ec2-user@ip-10-xxx-xxx-xxx]$ dig web1.aws.example.com ;; ANSWER SECTION: web1.aws.example.com. 300 IN CNAME ec2-54-xxx-xxx-xxx.ap-northeast-1.compute.amazonaws.com. ec2-54-xxx-xxx-xxx.ap-northeast-1.compute.amazonaws.com. 60 IN A 10.0.yyy.yyy
次に、AWS の外部で引いてみます。54.yyy.yyy.yyy というグローバル IP が引けました。
$ dig web1.aws.example.com (snip) ;; ANSWER SECTION: web1.aws.example.com. 300 IN CNAME ec2-54-xxx-xxx-x.ap-northeast-1.compute.amazonaws.com. ec2-54-xxx-xxx-x.ap-northeast-1.compute.amazonaws.com. 604800 IN A 54.yyy.yyy.yyy
どちらも正常に動作していることが確認できました。
4. 利用
アプリケーションやミドルウェアなどで、EC2 インスタンスへ接続する場合は、今回設定した web1.aws.example.com を設定します。AWS 内部であれば、ローカル IP が引けるので、内部ネットワークで接続できます。
動作確認などで、外部から接続する場合も同じく web1.aws.example.com へ接続します。AWS 外部であれば、グローバル IP が引けるので、該当インスタンスへ接続することができます。
5. Public DNS が変更した場合
EC2 インスタンスの再起動などで、Public DNS が変更になった場合は、Route 53 にて、web1.aws.example.com の Value を新しいインスタンスの Public DNS に設定するだけです。
さいごに
Route 53 で、EC2 インスタンスの Public DNS を設定する方法を見てきました。
ここでは、EC2 インスタンスの話を書いていますが、RDS や ElastiCache などのエンドポイントも同じように Route 53 で FQDN を割り当てておくと、もしエンドポイントが変更になった際も変更箇所が限定されているので楽です。
ただ、Route 53 に登録するということは、当然ながら、誰もが Public DNS を知ることができるという点は留意しておく必要があります。(もちろん、FQDN も知る必要がありますが)個人的には、Security Group で接続制限をかけていれば問題は無いと思いますが、これまずいんじゃない?というのがあれば、教えて下さい m(_ _)m
- コメント (Close): 0
- トラックバック (Close): 0
- Masashi Shinbara
-

- 執筆したもの
- 固定ページ
- 最近の投稿
- カテゴリー
- アーカイブ
-
- 2016-06
- 2016-02
- 2016-01
- 2015-12
- 2015-10
- 2015-09
- 2015-07
- 2015-06
- 2015-05
- 2015-04
- 2015-03
- 2015-01
- 2014-12
- 2014-11
- 2014-10
- 2014-09
- 2014-08
- 2014-07
- 2014-06
- 2014-05
- 2014-04
- 2014-03
- 2014-02
- 2014-01
- 2013-12
- 2013-11
- 2013-10
- 2013-09
- 2013-08
- 2013-07
- 2013-06
- 2013-05
- 2013-04
- 2013-03
- 2013-02
- 2013-01
- 2012-12
- 2012-11
- 2012-10
- 2012-09
- 2012-08
- 2012-06
- 2012-05
- 2012-03
- 2012-02
- 2012-01
- 2011-12
- 2011-11
- 2011-10
- 2011-08
- 2011-07
- 2011-06
- 2011-05
- 2011-04
- 2011-03
- 2011-02
- 2011-01
- 2010-12
- 2010-11
- 2010-10
- 2010-09
- 2010-08
- 2010-07
- 2010-06
- 2010-05
- 2010-04
- 2010-03
- 2010-02
- 2010-01
- 2009-12
- 2009-11
- 2009-10
- 2009-09
- 2009-08
- 2009-07
- 2009-06
- 2009-05
- 2009-04
- 2009-03
- 2008-12
- 2008-11
- 2008-10
- 2008-08
- 2008-07
- 2008-06
- 2008-05
- 2008-04
- 2008-03
- 2008-02
- 2008-01
- 2007-12
- 2007-11
- 2007-10
- 2007-09
- 2007-08
- 2007-07
- 2007-06
- 2007-05
- 2007-04
- 2007-03
- 2007-02
- 2007-01
- 2006-12
- 2006-11
- 2006-10
- 2006-09
- 2006-08
- 2006-07
- タグクラウド







- 検索
- フィード
- メタ情報