Home > cloud
cloud Archive
「Twilioを使えば簡単にできるアプリケーションと電話/SMS連携」を発表しました
第4回イノベーションエッグで、「Twilioを使えば簡単にできるアプリケーションと電話/SMS連携」という発表をしてきました。
![]()
発表資料
発表資料は以下です。
セッションでは、デモにて、Web アプリケーションから電話をかけたり、簡易 IVR で、コールセンター(を見立てた携帯電話)に電話をつないだり、SMS 送信を行ったりしました。
電話で簡単にデモできるのが、Twilio の良さですね。
さいごに
Twilio-UG という Twilio のユーザグループが立ち上がったので、2015/09月頃に大阪でもイベントを行う予定です。
Twilio は、電話や SMS という、デバイスは身近にあるのに、システムとどう連携するかが、Web の人間にはピンと来ないものを Web の文脈で簡単に利用することができます。
Twilio の使いどころとして、これを中心に据えるというより(コールセンター等は別として)、すでにある業務アプリケーションやサービスにあるコミュケーションに関する課題を解決するツールとして考えると、意外にはまる箇所はあると思っています。
エンジニアとしても、驚くほど簡単に電話と連携でき、使い方を想像するのが楽しいサービスなので、一度触ってみて下さい。
- コメント (Close): 0
- トラックバック (Close): 0
AWS で請求金額にビックリしないようにやっておくべきこと
- 2015-03-13 (金)
- AWS
AWS は、従量課金なので、他者からの不正利用(本来無いことですが)や想定外の利用で、翌月の請求が来て、ビックリということがあります。
![]()
私自身も関わっているプロジェクトで、ある月に平時の数倍の請求が来て、原因調査を行ったという経験がありました。
転ばぬ先の杖ということで、先にやっておくべきことについてまとめておきます。
1. AWSアカウントの不正利用を防ぐ
まず、考えられるのが、アカウントを乗っ取られての不正利用です。もちろん、不正利用は、請求だけでなく、システムやリソースを守るという点でも防ぐべきことです。
そこで、AWS アカウントは、2要素認証(2段階認証 / 2 Factor authentication / 2FA)を設定しておきます。
手順は、下記のエントリがまとまっています。
AWSアカウント作ったらこれだけはやっとけ!IAMユーザーとAuthyを使ったMFAで2段階認証 – Qiita
私は、以前は、Google Authenticator を使っていたのですが、Authy に変えました。単純に見やすいですし、バックアップ機能もあり、スマートフォン買い替えなどで別デバイスへ移行する際も便利なので、おすすめです。
2. アクセスキーを適切に管理する
AWS アカウントの不正利用を防いだところで、アクセスキーの管理がずさんだと、結局は不正利用されてしまいます。
そこで、アクセスキーを適切に管理する方法を知っておきます。
これについては、AWS のドキュメントに、良い資料があるので、こちらを参考にすると良いでしょう。
AWS アクセスキーを管理するためのベストプラクティス – アマゾン ウェブ サービス
3. 請求金額を監視する
これで、不正利用は防げて安心、というなるところなのですが、正規な利用を行っていても、驚きの請求が来ることがあります。
私が、遭遇したケースは、まさにこれでした。
某Webサイトでの出来事だったのですが、アクセス数はそれほど変わらないのに、転送量が平時の月より大幅に増えて、それにより予想外の請求が来ていました。よくよく調べてみると、このサイトでは動画ファイルを公開していたのですが、動画ファイルの容量が大きく、これが原因で転送量が増加していました。確認してみると、動画ファイルを更新した時期と、請求額が大きく増えた月が一致していました。
このように、不正利用では無くとも、通常の運用でも、請求額が大きく増える可能性は十分にあります。
運用を気をつけるというのはもちろんなのですが、Billing Alerts で、請求額を監視しておくと安心です。
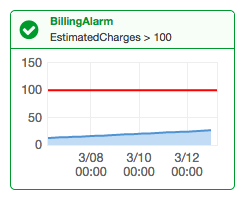
アラートと通知で請求額を監視 – AWS 請求情報とコスト管理
Billing Alerts は、月ごとの請求額を監視して、設定した値を超えれば、アラートを送るというものです。
私の場合、下記の 2 パターンでアラートが来る用意設定しています。
- $10 を超えたら、アラート通知
- 平時請求額 * 3 を超えたら、アラート通知
前者は、ちゃんとアラートが飛んでくるか確認するためです。監視にありがちな「頼りがないのは良い知らせ」と思って、安心してたら、実はちゃんと監視できていない( or アラート設定が間違っていた)を防ぐためです。
後者が、想定外の請求を監視するもので、これが飛んできたら、請求内容を確認して、想定外のリソースが使われていないかを確認します。
さいごに
AWS は、従量課金でかつプログラマブルにリソースを操作できるので、想定外なリソース利用によって、請求額が増加する可能性があります。ただ、請求金額すら、リソースと同じように監視して、アラートが出せるというのが AWS らしくて良いですね。
突然の請求に驚かないように、今一度、確認しておきましょう。
- コメント (Close): 0
- トラックバック (Close): 0
「Azure Websites で作るスケーラブルな PHP アプリケーション」を GoAzure 2015 で発表してきました
Azure コミュニティの一大イベント GoAzure 2015 にて、「Azure Websites で作るスケーラブルな PHP アプリケーション」という発表を行ってきました。

セッションでもお話したのですが、テーマは、もう一つあり、それは「LAMP(LAPP) ユーザが使う Azure Websites」でした。
Azure は、マイクロソフトのサービスなので、どうしても Windows に最適化されているイメージがあったのですが、普段 Mac で開発して、Linux にデプロイして、運用している人間でも、興味深いサービスであることを伝えようと考えました。
発表資料
発表資料は、こちらです。
発表冒頭で、Azure Websites を使っている方に挙手頂いたのですが、6-7 割の方から手が上がりました。Azure のイベントなので、当然といえば、そうなのですが、利用されているのが多いのだなと実感しました。
PHP で PaaS を使う
以前から、PHP を公式にサポートする PaaS はいくつかあったのですが、海外のサービスが多く、ドキュメントも英語版のみで、日本ではあまり使われていない印象でした。
PaaS の雄である Heroku が、2014 年に正式に PHP に対応したことで、今後、PHP でも PaaS を使うことが広がっていくでしょう。(Heroku も公式サイトは、英語ですが、日本語のブログ記事や書籍があります。)Heroku は、PaaS として非常によく出来ているのですが、残念ながら、日本国内にサーバがありません(2015/01/19現在)。
その点、Azure Websites は、日本国内(東日本と西日本)にサーバがあり、日本語のドキュメントもあるので、PHP で PaaS を使うなら、まずは試してみる価値はあります。
Azure Websites + PHP + New relic が利用できない
発表では、入れ忘れたのですが、困ったことを一つ。
Azure Websites は、Windows Server なので、Windows 版 PHP 用の DLL が無い拡張は利用することができません。主要な拡張は問題無いと思うのですが、私が触った範囲では、一つだけこの問題に当たりました。
それが、New Relic の PHP 拡張です。
Azure 自体は、New Relic と連携ができ、.NET 環境では利用できるようなのですが、New Relic の PHP 拡張は、Windows 版が無いため、利用することができませんでした。
New Relic for PHP の FAQ でも現在は対応されていないことが明示されています。New Relic は便利なので、ぜひ対応してもらいたいところです。
https://docs.newrelic.com/docs/agents/php-agent/getting-started/new-relic-php-faqs#windows
アーキテクチャを明示して欲しい
発表資料には入れていますが、一つの Websites 内にある各インスタンスでは、ストレージ(D ドライブ)が共有されているようです。
検証した結果では、おそらくそうであろうということは分かっていましたし、そうであるという情報も見聞きすることができました。
ただ、最後の裏取りとして、公式のドキュメントで、このことが明示されている箇所を探したのですが、残念ながら、見つけることができませんでした。
PaaS だから、裏側を知らなくても良いだろう、という考え方なのかもしれませんが、アプリケーションを作る上でも、構成を組むにしても重要な部分なので、はっきりと公式サイトで明示して欲しいと思いました。
実際、私自身も検証の段階で、このことを知らずに、想定したような結果が出ずに首を傾げるということを経験しました。
せっかく、共有ストレージのおかげで、スケールアウトが容易という特徴があるのですから、ちゃんと明示した方が双方にメリットがあるのではないでしょうか。
追記:2015/01/24
こちらの記事で共有ストレージであることが記載されているようです。https://msdn.microsoft.com/ja-jp/magazine/dn786914.aspx
さいごに
冒頭でも触れましたが、Azure は、以前は「Windows Azure」という名称だったため、どうしても「Windows ユーザのためのもの」という印象がありました。ただ、今回 Azure Websites を検証してみたところ、あくまでマイクロソフト社が運営しているというだけで、クラウドサービスの一つであるという認識に変わりました。
OSX や Linux 上でも動くコマンドラインツール(npm でインストール)があり、Azure Websites では、Git でデプロイができます。デプロイ時に任意のスクリプト(Bash)を実行することができるので、Composer やフレームワークでのマイグレーションなども自動化できます。
上手くやれば、わりと活用できるシーンはあると思うので、今後も使ってみたいと思います。
無料枠もあるので、まだの方は、ぜひ一度試してみてください。
- コメント (Close): 0
- トラックバック (Close): 0
2014 年に発表したセッションと資料まとめ
2014 年も残すは、あと 1 週間になりました。今年も様々なイベントで登壇しましたので、発表したセッションと資料をまとめてみます。

写真提供:久岡写真事務所
登壇イベント
2014/04/04 「わかってるフレームワーク Laravel」Laravel勉強会福岡
「わかってるフレームワーク Laravel」とうタイトルで発表しました。
Laravel で、とあるプロジェクトの開発が終わった後だったので、Laravel への良さを主観たっぷりでお話しました。
翌日の Laravel Meetup Tokyo と合わせて、一人 Laravel Japan ツアーでした:D
2014/04/05 「知っておくべき Auth オートログイン」 Laravel Meetup Tokyo vol.3
Laravel 4.1.25 以前にあった Auth フィルタ利用時のオートログインの問題点についてお話しました。
いくつかの前提条件は必要ですが、影響度が大きいので、「これはやばい」というのが伝わっていました。
なお、この問題は、4.1.26 にて修正されたので、現在は問題ありません。
Laravel ユーザなら知っておくべきAuthオートログインのこと
2014/04/12 「Vagrant ユーザのための Docker 入門」 第3回コンテナ型仮想化の情報交換会@大阪
Docker が盛り上がってきた時だったので、Vagrant ユーザを対象に Docker 入門をお話しました。
セッション途中でも活発に質問が飛び込んできたり、デモでコンテナ起動の速さに驚きの声があがったりで、盛り上がったのを覚えています。
「VagrantユーザのためのDocker入門」を発表してきました
2014/04/19 「最近なんだか、はてブがおかしい」俺聞け8 in Tokyo
資料未公開
当初は「Webエンジンアとしてご飯を食べていく」という内容を考えていたのですが、事前に、主催の @msng さんから「ブログに関する発表が多くて嬉しい」というコメントがあったので、ブロブに寄せようと内容を変えました:)
会場には、著名なブロガーの方が多く、みなさん同じようなことを感じているようで、発表後の情報交換が捗りました。
2014/04/24 「Vagrant 体験入門」DevLove関西
これから Vagrant を学ぶ方向けに、Vagrant 概要についての発表と体験ハンズオンを行いました。
Vagrant ハンズオンでは、みんなで同一拠点から一斉にプロビジョンを行うので、遅延やエラーが起こったり、環境の違い(Vagrant + VirtualBox が起動するまでの)でトラブルが発生したりで、毎回発見があります。
ハンズオンの資料は Qiita に公開しています。
Vagrant体験入門ハンズオン手順 – 2014/04/24 DevLove関西
2014/06/19 「Heroku で作るスケーラブルな PHP アプリケーション」第16回関西PHP勉強会
Heroku で PHP が正式サポートされたので、スケーラブルな構成をどう組むかという内容でお話しました。
その後、いくつかのプロジェクトで Heroku + PHP を使っているのですが、やはり PaaS として良くできていますね。まだ掴みきれていない部分もあるので、引き続き追いかけていきます。
Heroku で作るスケーラブルな PHP アプリケーション
2014/06/28 「PHPコードではなく PHPコードの「書き方」を知る」PHPカンファレンス関西2014
PHPカンファレンス関西の初心者向けセッションということで、FizzBuzz を題材に、関数化、クラス化、そして自動テストを書くという流れをお話しました。
「PHPコードではなくPHPコードの「書き方」を知る」を発表してきました
2014/07/05 「開発現場で活用する Vagrant」夏の JAWS-UG 三都物語 2014
関西での JAWS-UG イベント、三都物語でのセッションでした。JAWS-UG では久しぶりの発表になりました。
Vagrant を実際に使う例として、デモで実演しながらセッションを進めました。
会場がフランクな雰囲気で、話しやすかったのが印象的でした。あと Yo を使って、バーチャル拍手というかうなずきを送ってもらったりもしましたね。
2014/08/23 「Vagrant 心得 5 ヶ条」DevLove 甲子園 2014 西日本大会
資料未公開
DevLove 甲子園にて、Vagrant についてお話しました。ここでは、Vagrant を活用する上で、気をつけておくと良いことを 5 つにまとめました。
内容は、いずれ blog に書きたいと思います。
2014/10/11 「Ansible ではじめるサーバ作業の自動化」PHPカンファレンス 2014
PHP カンファレンスで、Ansible についてお話しました。発表を聴いた方からは、好意的なフィードバックが多く、「Chef を使っていましたが、Ansible 使ってみます!」という意見もあり、良かったです。
準備している時は、話したいことをどう上手くおさめるかを苦心したので、普段スピーカーをしているコミュニティの仲間から「うまくまとまっていましたね」と言ってもらえ、やはり見ている人には分かるんだなあと感じたりもしました。
このセッションを見た方から、別のイベントでの登壇についてお誘いがあったり、次につながったセッションでもありました。
「Ansibleではじめるサーバ作業の自動化」を発表してきました
2014/12/19 「ビルドサーバで使う Docker」DevLove 関西
年内最後の発表は、やはり Docker でした。今年は、ほんと Docker が躍進した一年でしたね。
Jenkins サーバでの活用例から、導入のポイントや設定方法などをお話しました。
「Jenkinsサーバで使う Docker」を発表してきました
ロクナナワークショップ 「Laravel で学ぶモダン PHP 開発講座」
11 月から、ロクナナワークショップさんにて「Laravel で学ぶモダン PHP 開発講座」という講座を行っています。
みっちり 1 日で、Vagrant や Composer の使い方、Laravel を使った REST API の実装、そして、その自動テストを書くという内容です。
すでに 2 回開催しているのですが、参加された方は熱心に課題に取り組まれていて、講師としても勉強になることが多いです。まとまった時間でじっくり課題をこなしていくので、これから学んでいこうという方にはおすすめです。
次回は 2015/02/17 に開催予定ですので、もし興味がある方は、ご参加下さい。
さいごに
今年を振り返ってみると、自分で名乗り出るよりも、お声がけ頂いて、登壇するという機会が増えました。お声がけ頂けるのは嬉しく、スケジュールやタイミングが許せば、できるだけお引き受けしたいです。
人前で話すというのは、準備も大変ですし、いつも緊張しますが、毎回色々な発見があり、また、終わった後は何ともいえない解放感というか充実感を感じることができます。聴いて頂いた方からのフィードバックも嬉しいものです。
今年も、セッションに参加して頂いた方、イベントにお声がけ頂いた方、本当にありがとうございました。
2015 年は、年始の 1/16 に GoAzure 2015 で登壇する予定です。Websites でスケーラブルな PHP アプリケーションを作るという内容ですので、ご参加お待ちしています!
- コメント (Close): 0
- トラックバック (Close): 0
CakePHP2 アプリケーションを Heroku で動かす設定
CakePHP2 アプリケーションを Heroku 上で動かす設定についてです。
![]()
以前のエントリにも書きましたが、Heroku で Web アプリケーションを動かす際に重要なのは、Web サーバ自体(Heroku では、Dyno)に、アプリケーションの状態(データ、セッション情報、ログ等)を保持させないということです。
Heroku の Dyno は、デプロイの際や、定常的な再起動により、破棄されるため、記録されたファイルは消えてしまいます。よって、こうしたデータファイルは、アドオンなど外部に記録する必要があります。
Heroku では、アドオンを活用するのがポイントですので、ここでは、主に CakePHP アプリケーションからこうしたアドオンと連携する方法を見ていきます。
Environments Library as a plugin
まず、開発環境と Heroku 環境で設定値を切り替えるために Environments Library as a plugin を使います。
https://github.com/josegonzalez/cakephp-environments
これは、CAKE_ENV という環境変数の値で、環境に応じて、データベースやキャッシュなどの設定を切り替えるものです。昨今のフレームワークではお馴染みの機能ですね。
ここでは、下記の設定について切り替えを行います。
- ログ
- データベース
- キャッシュ / セッション
このプラグインでは、まず Config/bootstrap/environments.php を作成します。このファイルで、環境毎の設定ファイルの読み込みを行います。下記では、Heroku 環境用の heroku.php と、開発環境用の development.php を読み込んでいます。
- Config/bootstrap/environments.php
<?php
CakePlugin::load('Environments');
App::uses('Environment', 'Environments.Lib');
include dirname(__FILE__) . DS . 'environments' . DS . 'heroku.php';
include dirname(__FILE__) . DS . 'environments' . DS . 'development.php';
Environment::start();
次に、Heroku 環境用の Config/bootstrap/environments/heroku.php です。
環境の設定は、Environment::configure() で行います。第一引数に環境名(CAKE_ENVで指定するもの)、第二引数は適用条件(true なら、CAKE_ENV に合致しなければデフォルトとして適用)、第三引数に設定値の連想配列(Configure::write() する)、第四引数にコールバックを指定します。
第三引数で設定する方法もあるのですが、より柔軟な設定を行うために、ここでは、第四引数のコールバックを指定します。実際の設定は、以降で順に指定していきます。
- Config/bootstrap/environments/heroku.php
<?php
Environment::configure('heroku', false, [
], function () {
// Heroku 用設定
});
開発環境用の Config/bootstrap/environments/development です。コールバックで、デフォルトの設定を記述しています。
- Config/bootstrap/environments/development.php
<?php
Environment::configure('development', true, [
], function () {
// Log settings
App::uses('CakeLog', 'Log');
CakeLog::config('debug', array(
'engine' => 'File',
'types' => array('notice', 'info', 'debug'),
'file' => 'debug',
));
CakeLog::config('error', array(
'engine' => 'File',
'types' => array('warning', 'error', 'critical', 'alert', 'emergency'),
'file' => 'error',
));
// Database settings
Configure::write('DATABASE_OPTIONS', [
'datasource' => 'Database/Postgres',
'persistent' => false,
'host' => 'localhost',
'login' => 'shin',
'password' => '',
'database' => 'app',
]);
Configure::write('TEST_DATABASE_OPTIONS', [
'datasource' => 'Database/Postgres',
'persistent' => false,
'host' => 'localhost',
'login' => 'shin',
'password' => '',
'database' => 'app_test',
]);
// Cache settings
Cache::config('default', array('engine' => 'File'));
});
次に、database.php での接続情報を、環境ごとに設定できるように下記のようにします。各環境ファイルで Configure::write()
した値を、DATABASE_CONFIG クラスに設定します。
- Config/database.php
class DATABASE_CONFIG {
public $default = [];
public $test = [];
public function __construct() {
$this->default = Configure::read('DATABASE_OPTIONS');
$this->test = Configure::read('TEST_DATABASE_OPTIONS');
}
}
このプラグインを有効にするために、bootstrap.phpを以下のように変更します。コメント部分は削除しています。
- Config/bootstrap.php
<?php
require_once __DIR__ . '/../vendor/autoload.php';
include __DIR__ . '/bootstrap/environments.php';
Configure::write('Dispatcher.filters', array(
'AssetDispatcher',
'CacheDispatcher'
));
Heroku で環境変数 CAKE_ENV をセット
このアプリケーションが、Heroku にデプロイした際に、heroku.php を利用するように、環境変数CAKE_ENVにherokuをセットします。これで、デプロイしたアプリケーションは、heroku 設定で動作するようになります。
$ heroku config:set CAKE_ENV=heroku
ログ
Heroku 環境でのログの設定です。ログは、ファイルではなく、標準出力もしくは標準エラー出力に出力します。
こうしておくと、heroku logs コマンドでログが確認できます。また、Papertail や FlyData のようにログを各サービスへ転送するアドオンを使うと、出力されたログを閲覧したり、S3 などに転送することができます。
ログは、まずは標準出力もしくは標準エラー出力にして、あとそれをどう活用するかは、アドオンに任せるという考え方です。
下記では、アプリケーションログを標準出力へ、エラー出力を標準エラー出力へ出力しています。
- Config/bootstrap/environments/heroku.php
<?php
Environment::configure('heroku', false, [
], function () {
// Log settings
App::uses('CakeLog', 'Log');
App::uses('ConsoleOutput', 'Console');
CakeLog::config('debug', [
'engine' => 'ConsoleLog',
'stream' => new ConsoleOutput(),
]);
CakeLog::config('error', [
'engine' => 'ConsoleLog',
'stream' => new ConsoleOutput('php://stderr'),
]);
});
あとは、アドオンと追加すれば、出力されたログがアドオンで利用できます。例えば、Papertrailを以下のコマンドで追加して、アプリケーションを動作させると、Papertrail の画面でログが確認できます。
$ heroku addons:add papertrail
データベース
Heroku のデータベースといえば、PostgreSQL なので、Heroku Postgres を使います。(もちろん、MySQL が良ければ、ClearDB なり、RDS なり使えます。)
$ heroku addons:add heroku-postgresql
Heroku 内では接続情報が環境変数で渡されるので、これをパースします。パースされた情報を、heroku.php で、Configure::write() で、セットしていきます。
- Config/bootstrap/environments/heroku.php
<?php
Environment::configure('heroku', false, [
], function () {
// Log settings
(snip)
// Database settings
if (empty(getenv('DATABASE_URL'))) {
throw new CakeException('no DATABASE_URL environment variable');
}
$url = parse_url(getenv('DATABASE_URL'));
Configure::write('DATABASE_OPTIONS', [
'datasource' => 'Database/Postgres',
'persistent' => false,
'host' => $url['host'],
'login' => $url['user'],
'password' => $url['pass'],
'database' => substr($url['path'], 1),
]);
});
キャッシュ / セッション
キャッシュ / セッションのデータストアには、Redis を使います。
ここでは、Redis サービスのアドオンとして、Redis To Go を利用します。
$ heroku addons:add redistogo
データベースと同じく、接続情報が環境変数で渡されるので、それをパース(ホスト、ポート、パスワード)して、セットするだけです。セッションハンドラには、Cache を使いたいので、その指定も行います。
これで、キャッシュもセッションも、Redis To Go に保存されます。
- Config/bootstrap/environments/heroku.php
<?php
Environment::configure('heroku', false, [
], function () {
// Log settings
(snip)
// Database settings
(snip)
// Cache settings
if (empty(getenv('REDISTOGO_URL'))) {
throw new CakeException('no REDISTOGO_URL environment variable');
}
$url = parse_url(getenv('REDISTOGO_URL'));
Cache::config('default', [
'engine' => 'Redis',
'server' => $url['host'],
'port' => $url['port'],
'compress' => false,
'password' => $url['pass'],
'serialize' => 'php'
]);
// Session Settings
Configure::write('Session', [
'defaults' => 'cache',
]);
});
さいごに
ベーシックな部分だけですが、Heroku で CakePHP アプリケーションを動かす設定を見てきました。
ここで紹介した以外では、メールやデータファイル(画像等)など、他にもアプリケーションでは必要なものがありますが、ほとんどのものは、ここで見てきたようにアドオンを活用することで実現できます。
こうした構成にしておけば、Dyno が再起動したり、インスタンス数を増減しても、アプリケーションデータはアドオンに保持されているので、動作に支障はありません。こうしたスケーラブルナ構成にしておくのが、Heroku のような PaaS を活用する肝ですね。
このエントリは、CakePHP Advent Calendar 2014 の 3 日目でした。まだ少し空き枠があるので、CakePHP な何かを書いてみてはどうでしょうか。
- コメント (Close): 0
- トラックバック (Close): 0
Ansible で EC2 インスタンスを起動して、Route53 に Public DNS を登録する
Ansible は、構成管理ツールとして認知されていますが、AWS 関連のモジュールが多数実装されており、各コンポーネントの起動や設定ができます。
![]()
このエントリでは、Ansible で、検証環境用の EC2 インスタンスを起動して、その Public DNS をRoute 53 に登録してみます。
以前書いたこのエントリの内容 を Ansible で自動化するイメージですね。
準備
今回は、AWS を操作するので、Python の AWS SDK である boto をインストールしておきます。boto は、pip なり、yum なりでインストールできます。
- OSX
$ pip install boto
- RHEL / CentOS
$ rpm -ivh http://ftp.riken.jp/Linux/fedora/epel/6/i386/epel-release-6-8.noarch.rpm $ yum -y install python-boto
AWS 認証情報
AWS 認証情報を設定します。
playbook に直接記載する方法もあるのですが、ここでは、boto の設定ファイルである ~/.boto に記述をします。こうしておけば、playbook では、認証情報を指定する必要がありません。
[Credentials] aws_access_key_id = xxxxxxxxxxxxxxx aws_secret_access_key = xxxxxxxxxxxxxxx
EC2 インスタンスの起動
Ansible で EC2 インスタンスを起動するには、ec2 モジュールを使います。
AWS 関連のモジュールを使う場合、対象のインベントリが指定できない場合がある(対象のホストをこのタスクで生成するので)ので、local connection として実行します。
ec2 モジュールには、EC2 インスタンスを起動するためのパラメータを指定します。下記では、VPC で、t2.micro インスタンスを指定しています。各パラメータについては、EC2 インスタンスを起動する際は、お馴染みのものなので、値を指定していきます。あとで識別できるように Name タグに ansible1 を設定しておきます。
ここで起動したインスタンスの Public DNS を、Route 53 に登録するので、register を使って、処理結果をec2という変数に格納しておきます。
- hosts: localhost
gather_facts: no
connection: local
tasks:
- name: Create ec2 instanse
ec2:
key_name: keyA
instance_type: t2.micro
image: ami-0xxxxx
monitoring: yes
wait: yes
region: ap-northeast-1
group_id: sg-xxxxxx
vpc_subnet_id: subnet-xxxxx
assign_public_ip: yes
instance_tags:
Name: ansible1
register: ec2
Route 53 に Public DNS を CNAME に登録
あらかじめ決められた FQDN でアクセスできるように、先ほど起動したインスタンスの Public DNS を CNAME として Route 53 に登録します。
Route 53 の操作には、route53 モジュールを使います。
EC2 インスタンスの情報は、ec2.instances に格納されているので、これを利用します。下記では、ansible1.dev.example.com という FQDN に対して、ec2 の Public DNS を CNAME で割り当てています。
- name: Set Public DNS to CNAME in Route53
route53:
command: create
zone: dev.example.com
type: CNAME
value: "{{ item.public_dns_name }}"
overwrite: yes
record: ansible1.dev.example.com
ttl: 300
with_items: ec2.instances
playbook の実行
この playbook を ansible-playbook コマンドで実行します。
local connection を使うのですが、インベントリファイルが必要になるので、作成しておきます。
$ cat > hosts <EOF 127.0.0.1 EOF
では、実行してみましょう。ansible-playbook コマンドを実行すると、2 つのタスクが処理されました。
$ ansible-playbook -i hosts aws.yml
PLAY [localhost] **************************************************************
TASK: [Create ec2 instanse] ***************************************************
changed: [localhost]
TASK: [Set Public DNS to CNAME in Route53] *********************************************
changed: [localhost] => (item={......})
PLAY RECAP ********************************************************************
localhost : ok=2 changed=2 unreachable=0 failed=0
AWS の Management Console を確認すると、Name タグに ansible1 が設定されたインスタンスが生成されていました。
![]()
Route 53 を見ると、想定したいた FQDN の CNAME に EC2 インスタンスの Public DNS が設定されていました。
![]()
起動済の EC2 を破棄
EC2 インスタンスを起動して、Route 53 に登録するという流れはできました。
ただ、このままだと、この playbook を実行する度に新しいインスタンスが作成されるので、不要なインスタンスが残り続けます。そこで、今回は検証環境ということで、古いインスタンスは破棄した後に、新しいインスタンスを作るという流れにします。
起動済のインスタンスを破棄するには、稼働中のインスタンス ID を取得する必要があります。インスタンス ID はec2_factsモジュールを実行します。このモジュールは、インスタンス内で実行するので、インスタンスをインベントリファイルに追加する必要があります。
これを手で行うと、インスタンスを起動するたびにインベントリファイルを書き換えることになるので、Dynamic Inventory を利用します。Dynamic Inventory は、インベントリ情報をスクリプト等で動的に生成することができる仕組みです。これを使うことで、AWS から稼働中のインスタンス情報を取得して、各インスタンスをインベントリとして、タスクを実行することができます。
Ansible のソースコードには、稼働中の EC2 インスタンス情報を取得するスクリプト(plugins/inventory/ec2.py, plugins/inventory/ec2.ini)が含まれているので、これを利用します。
https://github.com/ansible/ansible/blob/devel/plugins/inventory/ec2.py
https://github.com/ansible/ansible/blob/devel/plugins/inventory/ec2.ini
ec2.py はインベントリを取得するスクリプトで、ec2.ini がその設定ファイルです。
まず、ec2.ini の設定を変更します。ec2.py は、デフォルトでは取得した情報をキャッシュ仕組みになっているのですが、今回は実行時に最新の情報を取得したいので、このキャッシュを無効にします。
$ vim ec2.ini cache_max_age = 300 # デフォルトは 300 秒なので、0 にする ↓ cache_max_age = 0
次に、playbook にインスタンス情報を取得するタスクを追加します。このタスクは、先頭に記述しておきます。hosts には、tag_Name_ansible1を指定しています。これは ec2.py で動的に取得したインベントリの内、タグ Name の値が ansible1 のホストを対象にするということです。このように ec2.py では稼働中の全インスタンスを利用するだけでなく、タグやインスタンスタイプなど様々な切り口でインベントリを絞り込むことができます。
---
- hosts: tag_Name_ansible1
gather_facts: no
user: root
tasks:
- ec2_facts:
つづいて、取得したインスタンス情報を使って、インスタンスを破棄します。インスタンスの破棄には ec2 モジュールを利用します。state=absentを指定することで、instance_idsで指定したインスタンスが破棄されます。
下記では、with_items で、インスタンスID を指定しているので、タグ名が ansible1 のインスタンスは全て破棄されます。
- hosts: tag_Name_ansible1
gather_facts: no
connection: local
tasks:
- name: Remove ec2 previous instances
ec2: state=absent
region=ap-northeast-1
instance_ids={{ item }}
wait=true
with_items: ansible_ec2_instance_id
完成した playbook の実行
playbook が完成しました。実行してみましょう。
-iオプションで、ec2.py を指定して、下記のように実行します。
実行すると下記の流れでタスクが実行されていきます。これで、何度実行しても起動しているインスタンスは一つのみになりました。
- タグ名=ansible1 の EC2 インスタンス情報取得
- 1 で取得した EC2 インスタンスを破棄
- EC2 インスタンス作成
- 3 で作成したインスタンスの Public DNS を Route 53 に登録
$ ansible-playbook -i ec2.py aws.yml
PLAY [tag_Name_ansible1] ******************************************************
TASK: [ec2_facts ] ************************************************************
ok: [xxx.xxx.xxx.xxx]
PLAY [tag_Name_ansible1] ******************************************************
TASK: [Remove ec2 previous instances] *****************************************
changed: [xxx.xxx.xxx.xxx] => (item=i-xxxxxx)
PLAY [localhost] **************************************************************
TASK: [Create ec2 instanse] ***************************************************
changed: [localhost]
TASK: [Set Public DNS to CNAME in Route53] *********************************************
changed: [localhost] => (item={...})
PLAY RECAP ********************************************************************
xxx.xxx.xxx.xxx : ok=2 changed=1 unreachable=0 failed=0
localhost : ok=2 changed=2 unreachable=0 failed=0
最終的な playbook は以下です。
---
- hosts: tag_Name_ansible1
gather_facts: no
user: root
tasks:
- ec2_facts:
- hosts: tag_Name_ansible1
gather_facts: no
connection: local
tasks:
- name: Remove ec2 previous instances
ec2: state=absent
region=ap-northeast-1
instance_ids={{ item }}
wait=true
with_items: ansible_ec2_instance_id
- hosts: localhost
gather_facts: no
connection: local
tasks:
- name: Create ec2 instanse
ec2:
key_name: keyA
instance_type: t2.micro
image: ami-0xxxxx
monitoring: yes
wait: yes
region: ap-northeast-1
group_id: sg-xxxxxx
vpc_subnet_id: subnet-xxxxx
assign_public_ip: yes
instance_tags:
Name: ansible1
register: ec2
- name: Set Public DNS to CNAME in Route53
route53:
command: create
zone: dev.example.com
type: CNAME
value: "{{ item.public_dns_name }}"
overwrite: yes
record: ansible1.dev.example.com
ttl: 300
with_items: ec2.instances
さいごに
Ansible で AWS を操作してみました。
インスタンス情報の取得やその情報の利用(インスタンス破棄)などは少しコツが必要ですが、それさえ分かれば、思ったとおりに動作しました。はじめは同じことを Terraform で行っていたのですが、プロビジョンには Ansible を使っていたので、どうせなら Ansible で完結させようと思い、試してみました。
このエントリでは、AWS の操作のみ行っていますが、実際は、インスタンス生成後にプロビジョンやデプロイを行う playbook を挟む形になります。こうすれば、EC2 インスタンス生成、プロビジョン、デプロイが Ansible だけで行うことができます。
- コメント (Close): 0
- トラックバック (Close): 0
AWS EC2 インスタンス間の名前解決に Route 53 を使う
- 2014-09-05 (金)
- AWS
Route 53 に EC2 インスタンスの Public DNS を CNAME で登録して、それを EC2 インスタンス間での通信でも利用するという話です。
1. 前提
- EC2-Classic 環境
- EC2 インスタンスの接続情報(FQDN なり IP なり)は、AWS のメンテナンスによる再起動などで変更される。
- アプリケーションやミドルウェアで、別インスタンスに接続している場合、AWS から割り当てられる Public DNS や IP を設定ファイルなどに記述していると、変更の度に修正が必要になる。
- DNSサーバを立てようとしたが、そこまで変更の頻度は多くない(日常的にインスタンス数が増減するわけではない)ので、正直わざわざ立てるほどでも無い。また、DNS サーバの面倒も見たくない。
2. やりたいこと
- Route 53 で各ホストの接続情報を管理すれば、一元管理できるし、修正も一箇所で済む。
- DNS サーバの面倒を見る必要が無いし、自分で運用するより安心。(Route53 は、SLA 100%)
- EC2 インスタンスごとに FQDN を割り当てて、CNAME として EC2 インスタンスの Public DNS を設定する。
- Public DNS を設定するのは、同じ FQDN で、AWS 外部からはグローバル IP、内部ではプライベート IP を返せるようにするため。
- 外部からのアクセスは、Security Group で制限する。
3. 設定
3-1. Route 53 で、サブドメインを作る
まず、EC2 インスタンス用のサブドメインを作成します。これは FQDN の管理の都合上だけなので、すでに存在してるドメインに、CNAME レコードを追加しても問題無いです。
ここでは、example.com を保持しているとして、サブドメインとして aws.example.com を作成します。EC2 インスタンスは、web1.aws.example.com や db-master.aws.example.com などにします。
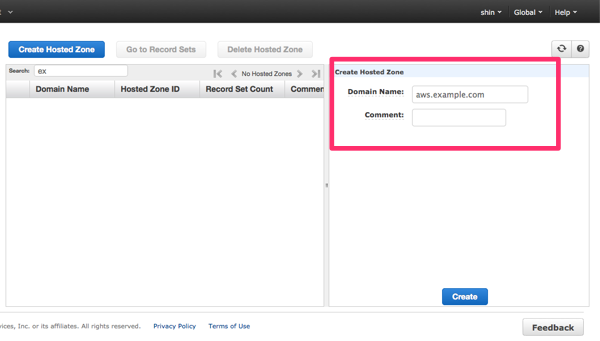
まず、Route 53 の画面で、「Create Hosted Zone」をクリックして、新しいゾーンを作成します。Domain Nameには今回作成するサブドメインを記述します。
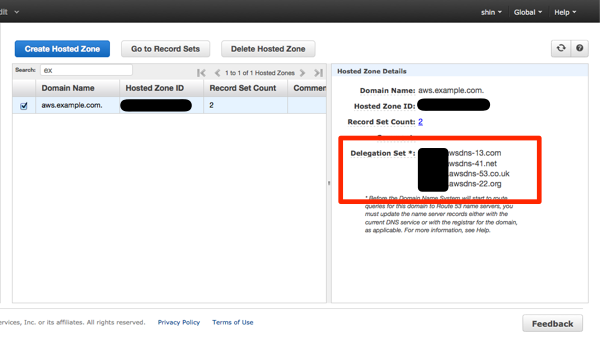
ゾーンを作成すると、Delegation Set が割り当てられます。これは後で、委譲先として設定するのでコピーしておきます。
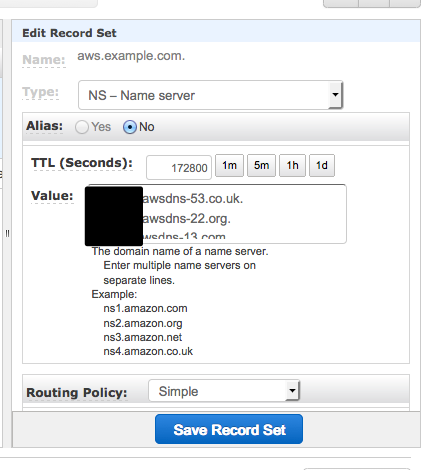
aws.example.com をサブドメインとして設定します。ここでは、example.com ドメインを Route 53 で管理している想定なので、それ以外の場合は、それぞれ適時設定して下さい。
すでにある exaple.com ゾーンを開いて、「Create Record Set」をクリックして、新しいレコードセットを作成します。画面右側のフォームで、「Name に aws を、Type に NS - Name server を入力します。Value には、先ほどコピーしておいた aws.example.com ゾーンの Delegation Set の内容をペーストします。
これで aws.example.com の設定ができました。
3-2. Route 53 で、EC2 インスタンスの FQDN を設定する
あとは、作成した aws.example.com に、レコードセットを追加して、EC2 インスタンスの Public DNS を CNAME として登録していくだけです。
ここでは、Web サーバとして使っている EC2 インスタンスの Public DNS を、web1.aws.example.com に割り当てます。
まず、EC2 の Public DNS を確認します。Management Console では下記のように表示されているので、これをコピーしておきます。

次に、Route 53 で、aws.example.com ゾーンを選択して、「Create Record Set」をクリックします。フォームには、以下のように、Name に web1、Type に CANE - Canonical name、Value に先ほどコピーした EC2 インスタンスの Public DNS を設定します。
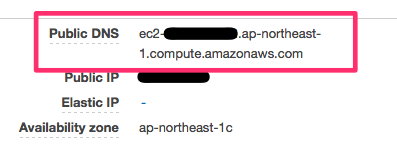
これで設定は完了です。
3-3. 動作確認
設定した FQDN が引けるかどうか確認します。(実際は、実在の FQDN で実行してますが、ここでは例示のため、exmaple.com ドメインとしています。)
まず、EC2 インスタンス内で引いてみます。こちらでは、10.0.yyy.yyy というローカル IP が引けました。
[ec2-user@ip-10-xxx-xxx-xxx]$ dig web1.aws.example.com ;; ANSWER SECTION: web1.aws.example.com. 300 IN CNAME ec2-54-xxx-xxx-xxx.ap-northeast-1.compute.amazonaws.com. ec2-54-xxx-xxx-xxx.ap-northeast-1.compute.amazonaws.com. 60 IN A 10.0.yyy.yyy
次に、AWS の外部で引いてみます。54.yyy.yyy.yyy というグローバル IP が引けました。
$ dig web1.aws.example.com (snip) ;; ANSWER SECTION: web1.aws.example.com. 300 IN CNAME ec2-54-xxx-xxx-x.ap-northeast-1.compute.amazonaws.com. ec2-54-xxx-xxx-x.ap-northeast-1.compute.amazonaws.com. 604800 IN A 54.yyy.yyy.yyy
どちらも正常に動作していることが確認できました。
4. 利用
アプリケーションやミドルウェアなどで、EC2 インスタンスへ接続する場合は、今回設定した web1.aws.example.com を設定します。AWS 内部であれば、ローカル IP が引けるので、内部ネットワークで接続できます。
動作確認などで、外部から接続する場合も同じく web1.aws.example.com へ接続します。AWS 外部であれば、グローバル IP が引けるので、該当インスタンスへ接続することができます。
5. Public DNS が変更した場合
EC2 インスタンスの再起動などで、Public DNS が変更になった場合は、Route 53 にて、web1.aws.example.com の Value を新しいインスタンスの Public DNS に設定するだけです。
さいごに
Route 53 で、EC2 インスタンスの Public DNS を設定する方法を見てきました。
ここでは、EC2 インスタンスの話を書いていますが、RDS や ElastiCache などのエンドポイントも同じように Route 53 で FQDN を割り当てておくと、もしエンドポイントが変更になった際も変更箇所が限定されているので楽です。
ただ、Route 53 に登録するということは、当然ながら、誰もが Public DNS を知ることができるという点は留意しておく必要があります。(もちろん、FQDN も知る必要がありますが)個人的には、Security Group で接続制限をかけていれば問題は無いと思いますが、これまずいんじゃない?というのがあれば、教えて下さい m(_ _)m
- コメント (Close): 0
- トラックバック (Close): 0
Laravel の Queue で非同期処理を実装する(beanstalkd / IronMQ / SQS)
Laravel で実装されている Queue について見てみました。

Laravel では Queue を使うことで、時間がかかる処理や、時間差で実行したい処理を非同期で実行することができます。
Laravel 4.2 の Queue では、以下の 5 つのキュードライバをサポートしています。
- sync
- Beanstalkd
- Amazon SQS
- IronMQ
- Redis
ここでは、sync、Beanstalkd、IronMQ、Amazon SQS について試してみました。
Laravel での設定
Laravel で Queue を使うには、app/config/queue.phpにて、利用するキューエンジンの選択、設定を行います。
もちろん他の設定と同じく、app/config/local/queue.phpやapp/config/production/queue.phpなど、環境に応じて設定を切り替えることも可能です。
下記が設定例です。defaultでは利用するキュードライバを指定します。指定できる値は、sync, beanstalkd, sqs, iron, redis の 5 種類です。
connectionsキーでは、それぞれのドライバについて接続情報を指定します。下記では、beanstalkdの接続情報を指定しています。
return [
'default' => 'beanstalkd',
'connections' => [
'beanstalkd' => [
'driver' => 'beanstalkd',
'host' => 'localhost',
'queue' => 'default',
'ttr' => 60,
],
],
];
キューへジョブを登録
キューへのジョブを登録するには、Queueクラスのpushメソッドを使います。
第一引数にはジョブを実行するワーカーのクラス名を、第二引数にはワーカーに渡すパラメータを指定します。
use CarbonCarbon;
Queue::push('MyWorker', ['message' => 'Hello!', 'date' => Carbon::now()]);
ここでは、ワーカーのクラス名のみを指定しているため、ジョブを実行する際はfireメソッドが呼ばれます。他にもMyWorker@doJobとすることで任意のメソッドを実行したり、クロージャを渡して、そのクロージャをワーカーとして実行したりできます。
詳しくはドキュメントを参照してください。
http://laravel.com/docs/queues
http://laravel4.kore1server.com/docs/42/queues
ワーカーの実装
ジョブを処理するワーカーとしてMyWorkerクラスを実装します。ワーカーは特定のクラスを継承する必要はなく、 POPO(Plain Old PHP Object)で良いです。
MyWorkerクラスにはfireメソッドを実装します。ジョブがキューに登録されると、リスナーからこのメソッドが呼ばれます。
第一引数にはジョブインスタンス、第二引数では、Queue::push()の第二引数で指定したパラメータが渡されます。ただ、このパラメータはジョブに入る時にjson_encode()されるので、オブジェクトのインスタンスはプロパティの連想配列となります。
下記の実装では、渡されたパラメータを元に文字列を生成して、echoで標準出力へ出力しているだけです。
ジョブが正常に完了したら、delete()メソッドで、ジョブを削除しておきます。これを行わないと同じジョブが何度も実行されています。
<?php
use CarbonCarbon;
use IlluminateQueueJobsJob;
class MyWorker
{
/**
* @param Job $job
* @param array $data
*/
public function fire(Job $job, array $data)
{
echo sprintf('[%s] %s at %s', Carbon::now(), $data['message'], $data['date']['date']) . PHP_EOL;
$job->delete();
}
}
キューの監視
キューを監視してワーカーを起動するリスナーを起動します。
Laravel では artisan コマンドですでに用意されているのでこれを利用します。
php artisan queue:listenコマンドを実行すると、キューを監視状態になります。この状態でキューにジョブが登録されていると、自動でワーカーが起動して処理が実行されます。
$ php artisan queue:listen
この状態でジョブが登録されると下記のように出力されます。
$ php artisan queue:listen [2014-08-14 16:52:35] Hello! at 2014-08-14 16:52:34.000000 Processed: MyWorker
このプロセスが終了しているとキューにジョブが登録されても実行されないので、supervisor や monit などで常時起動するように設定しておくと良いでしょう。
一定時間後に実行するジョブ
Queue::push()で登録したジョブは、リスナーが感知するとワーカーが起動して実行されます。
それとは別に、Queue::later()というメソッドを使うと、一定時間経過後に実行するジョブを登録することができます。
第一引数には、ジョブの実行を開始する時間を指定します。数値を渡すと秒数として認識され、その秒数が経過した際にジョブが実行されます。Carbonクラスのインスタンスを渡すとCarbonクラスで指定された日時に実行されるジョブとして登録されます。
第二引数と第三引数は、Queue::push()の第一引数と第二引数と同じです。
下記の例では、10秒後に実行されるジョブを登録しています。
Queue::later(10, 'MyWorker', ['message' => 'Delayed', 'date' => Carbon::now()]);
リスナー側では下記のような出力になります。[]内の日時と、atの後ろの日時で 10 秒ずれていることが分かります。
$ php artisan queue:listen [2014-08-14 16:52:45] Delayed at 2014-08-14 16:52:34.000000 Processed: MyWorker
これはローカルの beanstalkd での実行なのでずれが無いですが、IronMQ を利用した際は、数秒のずれがありました。多少のずれは発生するので、それを認識した上で利用すると良いでしょう。
サポートしているキュードライバ
Laravel でサポートしているキュードライバ(Redisを除く)を見てみましょう。
sync
デフォルトで指定されているドライバです。
仕組みとしてはキュー、ワーカーの流れを通るのですが、ジョブが登録されると、即時にワーカーが実行されます。
非同期処理にはならないので、実際にキューを使う場面では、他のドライバを利用する必要があります。
Beanstalkd
Beanstalkd は、オープンソースのキューイングシステムです。
利用するには、Beanstalkd 自体のインストールが必要になります。
Beanstalkd は、yum などパッケージでも公開されているので、利用するプラットフォームごとに選択してインストールすると良いです。
ここでは OSX 環境を想定して、Homebrew でインストールします。
$ brew install beanstalkd
beanstalkd を起動します。デフォルトではポート11300で待ち受けます。
$ beanstalkd
なお、beanstalkd は、デフォルトではキューの情報を永続化しません。このままだと beanstalkd が落ちるとキューの情報が消えてしまうので、本番環境などで運用する際は、永続化するように設定を行うのが良いです。
http://kr.github.io/beanstalkd/
Laravel で利用する際は、composer で下記のパッケージを追加しておきます。pda/pheanstalk は、3.x がリリースされていますが、Laravel 4.2 は、2.x 系にしか対応していないので、バージョン番号に注意して下さい。
"require": {
"pda/pheanstalk": "~2.1.0"
}
IronMQ
Iron.io が提供しているメッセージキューサービスです。
ブラウザから登録するだけで利用することができます。基本は有償サービスなのですが、無料プランが用意されており、1,000,000APIリクエスト/月まで利用することができます。
グラフィカルな管理画面が用意されており、キューの状況などが分かりやすいのが良いです。
Heroku の Addon としても提供されているので、Heroku へデプロイするなら簡単に連携することができます。
Laravel で利用する際は、composer で下記のパッケージを追加しておきます。
"require": {
"iron-io/iron_mq": "~1.5.1"
}
下記が Heroku 環境で IronMQ を利用する際の設定例です。Heroku では、接続情報が環境変数で提供されてるので、それらをtokenとprojectに設定しています。
return [
'default' => 'iron',
'connections' => [
'iron' => [
'driver' => 'iron',
'host' => 'mq-aws-us-east-1.iron.io',
'token' => getenv('IRON_MQ_TOKEN'),
'project' => getenv('IRON_MQ_PROJECT_ID'),
'queue' => 'sample',
'encrypt' => true,
],
],
];
AWS US-East、AWS EU-West、Rackspace ORD、Rackspace LONのインスタンスを利用することができます。日本国内のインスタンスは存在しないので、国内のアプリケーションからキューを登録する場合はレイテンシが気になるかもしれません。
SQS
AWS のメッセージキューサービスです。
こちらも管理画面からキューを作成するだけで利用することができます。有償サービスですが、無料枠が用意されており、100万件キューイングリクエスト/月まで無料で利用することができます。
東京リージョンを利用できるので、アプリケーションサーバが国内にあるなら利用しやすいですね。
Laravel で利用する際は、composer で下記のパッケージを追加しておきます。
"require": {
"aws/aws-sdk-php-laravel": "1.*"
}
設定例は下記です。ここでは、アクセスキーやシークレット、エンドポイントURL を環境変数で渡しています。AWS ではおなじみですが、regionにキューを作成したリージョンを指定するのを忘れないようにしましょう。
'default' => 'sqs',
'connections' => [
'sqs' => [
'driver' => 'sqs',
'key' => getenv('AWS_ACCESS_KEY_ID'),
'secret' => getenv('AWS_SECRET_ACCESS_KEY'),
'queue' => getenv('AWS_SQS_URL'),
'region' => 'ap-northeast-1',
],
],
ユニットテスト
キューにジョブを登録する側のテストについてです。
QueueクラスをshouldReceiveメソッドでモック化して、テストするのが手軽です。
<?php
use CarbonCarbon;
/**
* Class QueueTest
*/
class QueueTest extends TestCase
{
/**
* @test
*/
public function queuePush()
{
$now = Carbon::create(2014, 8, 13, 12, 34, 56);
Carbon::setTestNow($now);
Queue::shouldReceive('connected')->once();
Queue::shouldReceive('push')->once()->with('MyWorker', ['message' => 'Hello!', 'date' => $now]);
Queue::shouldReceive('later')->once()->with(10, 'MyWorker', ['message' => 'Delayed', 'date' => $now]);
$this->client->request('GET', '/queue/push');
$this->assertTrue($this->client->getResponse()->isOk());
}
}
サンプルアプリケーション(Heroku)
このエントリの内容を実装したサンプルアプリケーションを github に公開しています。
コード自体はシンプルで、http://localhost/quque/push にアクセスするとジョブがキューに登録されます。あとは php artisan queue:listen コマンドでジョブが実行されます。
Heroku で試せるように、heroku_create というシェルスクリプトで、heroku 関連のコマンドを記述しています。このコマンドを流せば、Heroku アプリケーションが構築されます。
Heroku でのポイントは、`Procfile`で、ワーカープロセスとしてリスナーを起動するという点です。
web: vendor/bin/heroku-php-apache2 public/
worker: php artisan queue:listen
このアプリケーションを Heroku にデプロイすると、web(ジョブをキューに登録する側)、worker(リスナー)の Dyno が構築されます。
あとは Heroku の管理画面で worker の Dyno 数を 1 にすると、web 経由で登録したジョブが worker によって実行されるようになります。
https://github.com/shin1x1/laravel-queue-sample
さいごに
Laravel の Queue について見てきました。
最後に、どのドライバを使うかについてですが、開発環境では beanstalkd を利用するのが手軽で良いでしょう。ローカルにインストールするので動作も速いです。
本番環境では、要件によりけりですが、国内にアプリケーションサーバがあるなら SQS、Heroku など US リージョンを利用するなら IronMQ が良さそうです。
もちろん、自前で beantalkd や Redis を立てるのも良いですが、利用できるなら、ありものを利用するのが楽ですね。
このように、開発環境と本番環境とでドライバを変えても、コード側は一切変更する必要が無いというのは、よく出来ていますね。
参考
blog.ISHINAO.net | Laravel 4でキューを使ってみる
laravel – キュードライバにbeanstalkdを使用する – Qiita
- コメント (Close): 0
- トラックバック (Close): 0
Heroku で作るスケーラブルな PHP アプリケーション
第16回関西PHP勉強会で、「Heroku で作るスケーラブルな PHP アプリケーション」という発表をしてきました。
![]()
発表資料
Heroku でちゃんと動く PHP アプリケーションを作ると、自然とスケーラブルな構成になりますよ、という内容です。
会場でも、Heroku 自体は知っているが、まだ使ってはいないという人が多かったので、細かな Tips は省いて、こういった構成でやりますよというイメージをお話しました。
実際に構築する上での Tips などは、また別の機会に話してみたいです。
サンプルアプリケーション
サンプルアプリケーションとして、簡単な画像アップロードサイトを Laravel 4.2 で作りました。
https://github.com/shin1x1/laravel-on-heroku
アプリケーションデータは、以下のアドオンへ保存するようにしています。画像ファイルは、アドオンではなく、S3 に保存しています。
- データベース = Heroku Postgres
- ログ = Papertrail
- セッションストレージ = Redis To Go
- 画像ファイル = S3(AWS)
使い方は、README.md に記載しているのですが、Heroku 関係は、heroku_create というシェルスクリプトにまとめています。
これを流せば、Heroku アプリケーションの作成、環境変数追加、アドオン追加などをひと息で行うことができます。
#!/bin/sh heroku create -r heroku heroku config:set LARAVEL_ENV=heroku heroku addons:add heroku-postgresql heroku addons:add newrelic:stark heroku addons:add scheduler heroku addons:add sendgrid heroku addons:add redistogo heroku addons:add papertrail heroku addons:add librato
デモ用に Heroku にデプロイしています。
http://infinite-caverns-8536.herokuapp.com/
さいごに
Heroku は、無料から使えるのが良いですね。アドオンも機能制限(保存レコード数等)版ながら無料で使えるものが多いので、アプリケーションからの連携を試すことができます。
スケーラブルな PHP アプリケーションを作る練習場として、Heroku を触ってみるというのも面白いですよ。
- コメント (Close): 0
- トラックバック (Close): 0
Heroku で Composer を使う時に気を付けたいこと
Heroku が PHP をサポートしたので、テストがてら Laravel アプリケーションをデプロイしてみました。
![]()
デプロイしたのは、Doctrine を利用するアプリケーションだったのですが、ローカルでは composer でインストールできるのですが、Heroku にデプロイするとインストールされないという現象が起こりました。
Laravel での Doctrine 使用
今回のアプリケーションでは、DBのテーブルスキーマ情報を読み込んで、動的に画面を作るという処理があり、そこで Doctrine の SchemaManager を使っていました。
Laravel で、Doctrine の SchemaManager のインスタンスを取得するのは簡単で、下記のメソッドを実行するだけです。
$manager = DB::connection()->getDoctrineSchemaManager();
こんなあっさりなので、laravel/frameworkパッケージをインストールすると、Doctrine も入るものだと思ってました。
Heroku での Composer
Heroku へデプロイするコードのルートディレクトリにcomposer.jsonが含まれていると、PHPアプリケショーンとしてセットアップが行われます。(依存解決に Composer を使わない場合でも、空のcomposer.jsonが必要です。)
このcomposer.jsonでは、通常の依存関係を指定するだけでなく、実行するPHPバージョンや拡張の指定ができます。例えば、下記のようにするとPHP 5.5.12をランタイムにして、memcached拡張が利用できます。
{
"require": {
"php": "5.5.12"
"ext-memcached": "*",
}
}
この記法は、Composer としてはサポートしているのですが、Composer 自身がランタイムの変更などを行うわけではありません。
そこで、Heroku の Composer は独自拡張しているのだろうと考えました。まあ、この思い込みが惑わすわけですが。
あと、Heroku での PHP サポートは、まだベータなので、そのせいもあるのかなと思ってました。
https://getcomposer.org/doc/02-libraries.md#platform-packages
開発環境、別 PaaS では正常に動作
もちろん開発環境(OSX, Linux VM)では、Heroku にデプロイしたものと同じコード(composer.(json|lock))で問題無く動いていました。
別のPaaSを試してみようと思い、Pagodabox に設置すると、これも正常に動作しました。
Heroku と 別 PaaS で、vendor/ 以下を比べると、10個近くのパッケージがHerokuでは入っていませんでした。
なぜ Heroku だけ入らない。やっぱり、独自拡張のせい?ベータ版だから?
–no-dev!
この作業していたのが、夜中でした。Pagodabox にデプロイできたので、これで良しとして、その日は寝ました。
しかし、気になるのが、同じ現象をググっても、Laravel アプリケショーンが Heroku で動かない,
Doctrine が入らないなんて出てこないんですね。動かしてみた系の記事はあるのに。
翌日、もう一度、Heroku の公式のドキュメントを読み直すことにしました。
すると、ありました。ちゃんと書いてありました。実行する composer コマンドが。
Heroku では、下記のオプション付きで実行するようです。そう、--no-devオプション付きでね!
$ composer install --no-dev --prefer-dist --optimize-autoloader --no-interaction
早速、手元で同じオプションで実行してみると、ちゃんとDoctrineがインストールされない。
ああ、これか。。。
Heroku PHP Support | Heroku Dev Center
–no-dev オプション
composer コマンドでは、いくつかオプションを指定することができ、--no-devはその一つです。
Composer公式サイトでは、下記の記述があります。--no-devオプションを付けると、依存解決する際にcomposer.jsonのrequire-devセクションの内容は解決されません。
--no-dev: Skip installing packages listed in require-dev.
デフォルトでは、--devが付いているのと同じ状態になり、require-devセクションの内容も依存解決の対象となります。
https://getcomposer.org/doc/03-cli.md#install
依存パッケージのcomposer.jsonをチェック
アプリケーションが依存しているパッケージのcomposer.jsonを洗い出してみると、require-devにDoctrineを指定しているものはいくつかあれど、requireに指定しているものは見事にありませんでした。
つまり、開発環境やPagodaboxでは、--no-dev無しだったため、require-devセクションを含んで依存解決したため、Doctrine が入っていました。
かたや、Heroku では、--no-devありだったので、Doctrine が入りませんでした。おそらく Heroku だけに入らなかった他のパッケージも同様でしょう。
[解決] require に doctrine を指定
はい、原因は分かったので、解決方法です。
composer.jsonのrequireに、Doctrine を追加しました。
"require": {
"php": ">=5.4.0",
"laravel/framework": "4.1.*",
"doctrine/dbal": "~2.3" // <--- 追加!
},
Heroku にデプロイすると、バッチリ動きました!Herokuさん、疑ってゴメン。
実際にデプロイしたものが下記です。
http://laravel-table-admin.herokuapp.com/crud/classes
コードは、Github で公開しています。Heroku でも Pagodabox でもデプロイできているので、両 PaaS にPHPアプリケーションをデプロイする際は参考にどうぞ。
https://github.com/shin1x1/laravel-table-admin-example
さいごに
まあ分かってしまえば、単純というよくある話です。
Heroku が Composer を拡張しているかどうかは分かりませんが、ドキュメントには、composer 実行前に self-update しているという記述もあるので、Composer は標準のもので、別途compoer.jsonを見てランタイムを決定するシステムがあるのかもしれません。
あと、夜中に躓いたら、さっさと寝るということですね。睡眠大事。
追記
”別途compoer.jsonを見てランタイムを決定するシステム”は多分この辺だと思う https://t.co/t5qXCkwKuH Heroku で Composer を使う時に気を付けたいこと http://t.co/vJRlTTV5Q6 @shin1x1さんから
— ISHIDA Akio (@iakio) 2014, 5月 26
ラインタイムや拡張を実際に指定する処理は、PHP の buildpack に記述がありました。@iakio さん、ありがとうございました!
- ラインタイムの決定(PHPバージョン or HHVM)
https://github.com/heroku/heroku-buildpack-php/blob/master/bin/compile#L106-L133 - 有効にする拡張の決定
https://github.com/heroku/heroku-buildpack-php/blob/master/bin/compile#L185-L208
- コメント (Close): 0
- トラックバック (Close): 0
ホーム > cloud
- Masashi Shinbara
-

- 執筆したもの
- 固定ページ
- 最近の投稿
- カテゴリー
- アーカイブ
-
- 2016-06
- 2016-02
- 2016-01
- 2015-12
- 2015-10
- 2015-09
- 2015-07
- 2015-06
- 2015-05
- 2015-04
- 2015-03
- 2015-01
- 2014-12
- 2014-11
- 2014-10
- 2014-09
- 2014-08
- 2014-07
- 2014-06
- 2014-05
- 2014-04
- 2014-03
- 2014-02
- 2014-01
- 2013-12
- 2013-11
- 2013-10
- 2013-09
- 2013-08
- 2013-07
- 2013-06
- 2013-05
- 2013-04
- 2013-03
- 2013-02
- 2013-01
- 2012-12
- 2012-11
- 2012-10
- 2012-09
- 2012-08
- 2012-06
- 2012-05
- 2012-03
- 2012-02
- 2012-01
- 2011-12
- 2011-11
- 2011-10
- 2011-08
- 2011-07
- 2011-06
- 2011-05
- 2011-04
- 2011-03
- 2011-02
- 2011-01
- 2010-12
- 2010-11
- 2010-10
- 2010-09
- 2010-08
- 2010-07
- 2010-06
- 2010-05
- 2010-04
- 2010-03
- 2010-02
- 2010-01
- 2009-12
- 2009-11
- 2009-10
- 2009-09
- 2009-08
- 2009-07
- 2009-06
- 2009-05
- 2009-04
- 2009-03
- 2008-12
- 2008-11
- 2008-10
- 2008-08
- 2008-07
- 2008-06
- 2008-05
- 2008-04
- 2008-03
- 2008-02
- 2008-01
- 2007-12
- 2007-11
- 2007-10
- 2007-09
- 2007-08
- 2007-07
- 2007-06
- 2007-05
- 2007-04
- 2007-03
- 2007-02
- 2007-01
- 2006-12
- 2006-11
- 2006-10
- 2006-09
- 2006-08
- 2006-07
- タグクラウド







- 検索
- フィード
- メタ情報